JavaSE-SpringBoot知识点 跟着三更学JAVA-基础篇 第一部分:基本数据类型 类型
类型名称
字节空间
取值范围
整数型
byte
1字节(8位)
-128到127 或者 -2^(8-1)到2^7
short
2
-2^15到2^15-1
int
4
-2^31到2^31-1
long
8
-2^63到2^63-1
浮点型
float
4
单精度,对小数点精确度不够高
double
8
双精度,对小数点精确度高
字符型
char
2
0到65535
boolean
1
true或false
引用数据类型 :数组,String
整数默认为int,小数默认为double
Java 有哪些数据类型? 定义: Java 语言是强类型语言,对于每一种数据都定义了明确的具体的数据类型,在内存中分配了不同大小的内存空间。
Java 语言数据类型分为两种:基本数据类型 和引用数据类型 。
基本数据类型:
数值型
整数类型(byte、short、int、long)
浮点类型(float、double)
字符型(char)
布尔型(boolean)
Java 基本数据类型范围和默认值:
基本类型
位数
字节
默认值
int32
4
0
short16
2
0
long64
8
0L
byte8
1
0
char16
2
‘u0000’
float32
4
0f
double64
8
0d
boolean8
1
false
引用数据类型:
类(class)
接口(interface)
数组([])
第二部分:数组 动态初始化 (长度确定推荐用)String[] arr = new String[3];初始化字符串数组为3的数组,String为引用数据类型,初始值为null
int[] arr = new int[3];初始化整形数组为3的数组,int的初始值为0
静态初始化 (已经确定元素值推荐使用)String[] arr = {“kang”,”wang”,”wei”};
int[] arr = {1,2,3,4};
数组元素的表示 arr[0] = 1;
arr[2] = 3;
介绍堆栈 栈 :方法调用都要进栈,局部变量(方法当中定义的变量)都存储在栈中
堆 :new出来的东西都在堆中
数组的内存图
数组的实体保存在堆中,数组名实际保存的是数组实体所对应的地址值
数组中最大值
用擂台法,将数组第一个值作为擂主,依次让下一个数进入擂台,大于擂台上的数就成为擂主,最后打印这个擂主(从第二个数开始,分别拿元素值和max比较,如果元素值大于max。就把元素值赋值给max)
1 2 3 4 5 6 7 int max = arr[0 ];for (int i = 0 ; i< arr.length; i++){ if (arr[i]>max) { max = arr[i]; } }
练习2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public static void main (String[] args) { int [] arr = new int [10 ]; Scanner sc = new Scanner (System.in); for (int i = 0 ; i < arr.length; i++) { arr[i] = sc.nextInt(); } int sum = 0 ; int max = arr[0 ]; int min = arr[0 ]; for (int i = 0 ; i < arr.length; i++) { sum += arr[i]; if (arr[i]>max) { max = arr[i]; } if (arr[i]<min) { min = arr[i]; } } System.out.println("sum = " + sum); System.out.println("max = " + max); System.out.println("min = " + min);
练习4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int [] arr = {171 ,72 ,19 ,16 ,118 ,51 ,210 ,7 ,18 }; int sum = 0 ; for (int i = 0 ; i < arr.length; i++) { if (arr[i]%10 !=7 &&arr[i]/10 %10 !=7 &&arr[i]%2 ==0 ) { System.out.println("i = " + arr[i]); sum += arr[i]; } } System.out.println("sum = " + sum);
冒泡排序 对数组元素从大到小进行排序
冒泡排序:从第一个开始往后一个进行比较,小就互换,直到最后一个数是最小的。再循环一次倒数第二个最小…..依次进行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int [] arr1 = {5 ,7 ,3 ,13 ,43 };for (int j = 0 ; j < arr1.length-1 ; j++) { for (int i = 0 ; i < arr1.length - 1 - j; i++) { if (arr1[i] < arr1[i + 1 ]) { int temp = arr1[i]; arr1[i] = arr1[i + 1 ]; arr1[i + 1 ] = temp; } } } for (int i = 0 ; i < arr1.length; i++) { System.out.println("arr1 = " + arr1[i]); }
不死神兔 1 2 3 4 5 6 7 8 9 10 int [] arr3 = new int [20 ];arr3[0 ] = 1 ; arr3[1 ] = 1 ; for (int i = 2 ; i <arr3.length; i++) { arr3[i] = arr3[i-1 ]+arr3[i-2 ]; } System.out.println(arr3[19 ]);
第三部分:方法 方法定义格式: 1 2 3 4 修饰符 返回类型 变量名 (形参){ 方法体; return 返回值; }
第四部分:面向对象 this关键字 this关键字:this可以区分成员变量和局部变量,加了this关键字的是成员变量。
this关键字只能在一个类的成员方法和构造方法中使用
this关键字代表着什么呢?
哪个对象调用成员方法,就代表那个对象
构造方法和set方法 构造方法初始化给对象赋值,不能再通过构造方法赋值。
1 2 3 4 5 Student s = new ("张三" ,19 );s = new ("李四" ,20 );
但是可以通过set方法给对象重新赋值。
1 2 3 4 5 Student s = new ("张三" ,19 );s.setName="李四" ; s.setAge=20 ;
this和super关键字
多态 同一个数据类型的不同对象对同一行为有着不同的表现
比如动物(猫、狗对叫和吃有不同的表现)
三个条件:
父类引用指向子类对象
方法的重写(子类重写父类的方法)
方法的继承
访问特点
向上转型和向下转型
instanceof进行类型判断
1 2 3 4 5 6 7 8 9 10 11 if(对象 instanceof 类名/接口名) { } if (a instanceof Dog) { //a属于狗,将a强转为狗 Dog dog = Dog(a); } if (a instanceof Cat) { //a属于猫,将a强转为猫 Cat cat = Cat(a); }
static关键字
static是一个修饰符,被其修饰的成员就属于类了,会被类所有的对象共享
加了static的变量,可以用类名.变量名/方法名调用
无需构建实例对象就可以调用这个方法或者变量
静态方法不能访问非静态的成员
静态方法中不能有this关键字
final
修饰类、成员方法、局部变量、成员变量
不能继承、不能重写、变为常量赋值之后不能改变、 成员变量必须初始化。有两种初始化方式,一种是直接赋值另一种是再类的所有构造方法中对其赋值
abstract
abstract在方法中加入,然后可以提示·让这个方法来重写
当一个类有一个方法,这个方法在不同的子类中都有不同的实现的时候,在父类中我们没有去写具体的方法体,这个时候就可以使用抽象(不写方法体)
父类方法有个抽象方法,子类必须重写这个抽象方法
注意
抽象类可以有抽象方法
抽象类不能够直接创建对象
父类方法有个抽象方法,子类必须重写这个抽象方法或者把这个子类定义成抽象类
接口
变量为 public static final
方法为 public abstract
接口新增成员
默认方法
默认方法可以有方法体,可以选择不进行重写 default
如果两个接口中有相同的默认方法,一个类同时实现了这个两个接口,必须也要重写该方法
静态方法
不让实现类去重写该方法。直接用方法接口.这个方法来体现 static
私有方法(jdk9以上)
可以存在方法体,方法不可以被重写 private
private static void privateMethod(){
}
private void privateMethod(){
}
对默认方法和静态方法中的代码进行抽取,提高代码的复用
继承和接口的关系
继承单继承
一个类可以实现多个接口
抽象类和接口的区别
代码块
局部代码块
控制局部变量的生命周期,想让它再使用完之后尽快销毁,可以把局部变量定义在局部代码块当中,在局部代码块之外不能访问局部代码块里面的内容
1 2 3 4 5 public void test () { { System.out.println("这是局部代码块" ); } }
构造代码块
创建对象的时候先执行静态代码块,再执行构造方法
构造方法当中重复的代码,放到构造代码块当中,让其先执行,解决代码重复度
(用来抽取构造方法中的重复代码,提高代码的复用性)
1 2 3 { System.out.println("这是构造代码块" ); }
静态代码块
调用时机:在类的加载的时候会执行,同一个类在程序运行过程中只会加载一次,所以静态代码块也只会执行一次,并且执行顺序是在构造代码块之前的
用来给类当中的静态成员变量初始化,来避免用类名调用这个变量的时候没有被初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class Demo { String name; int age; static int staticNum; static { staticNum = 10 ; System.out.println("这里是静态代码块" ); } { age=1 ; System.out.println("这里是构造代码块" ); } public Demo (String name) { this .name = name; } public Demo () { } public void test () { { System.out.println("这是局部代码块" ); } } }
内部类
局部内部类
如果想定义一个在方法中临时使用的累时可以使用局部内部类
换句话说,如果只想让一个方法使用一个类的另一个方法时,定义局部内部类。
注意事项:局部内部类可以使用外部局部(事实)常量 final
成员内部类
在一个类中定义另外一个类(成员内部类),成员内部类可以访问外部类的私有变量
外部类名.this.成员名来表示外部类的成员
成员内部类不能定义静态成员(非静态中不使用静态)
应用场景:一个类不会单独使用,需要和另外的类一起使用才有意义,并且在用到外部类中的私有方法的时候,可以把这个类定义成内部类
IntegerCache
静态内部类
静态内部类里面可以定义静态成员变量和静态成员方法
静态内部类可以调用外部类的(私有的)静态成员变量(事实常量)
匿名内部类
1 2 3 new 接口名/类名(){要重写的方法(抽象方法) };
如果需要创建一个类或者接口的子类对象。但是这个子类只会使用一次,就没有必要创建单独的类。可以使用匿名内部类的形式。
匿名内部类就相当于一个对象,他是某个类(接口)的子类(实现类)的对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public class Demo02 { private static int age = 12 ; public Inter createItr () { Inter inter = new Inter (); return inter; } class Inter { String s; int age; Demo02.this .age; public Inter () { } public Inter (String s, int age) { this .s = s; this .age = age; } } static class staticMethod { public static void testMe () { System.out.println(age); } } public static void main (String[] args) { new Runner (){ @Override public void run () { System.out.println("正在运行" ); } }.run(); } }
第五部分:常用类 equals和==的区别 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 一、对象类型不同 1、equals():是超类Object中的方法。 2、==:是操作符。 二、比较的对象不同 1、equals():用来检测两个对象是否相等,即两个对象的内容是否相等。 2、==:用于比较引用和比较基本数据类型时具有不同的功能,具体如下: (1)、基础数据类型:比较的是他们的值是否相等,比如两个int类型的变量,比较的是变量的值是否一样。 (2)、引用数据类型:比较的是引用的地址是否相同,比如说新建了两个User对象,比较的是两个User的地址是否一样。 三、运行速度不同 1、equals():没有==运行速度快。 2、==:运行速度比equals()快,因为==只是比较引用。 扩展资料: equals()和==的源码定义: public boolean equals(Object obj) { return (this == obj); } 由equals的源码可以看出这里定义的equals与==是等效的(Object类中的equals没什么区别),不同的原因就在于有些类(像String、Integer等类)对equals进行了重写。 但是没有对equals进行重写的类就只能从Object类中继承equals方法,其equals方法与==就也是等效的,除非在此类中重写equals。 对equals重新需要注意五点: 1、自反性:对任意引用值X,x.equals(x)的返回值一定为true; 2、对称性:对于任何引用值x,y,当且仅当y.equals(x)返回值为true时,x.equals(y)的返回值一定为true; 3、传递性:如果x.equals(y)=true, y.equals(z)=true,则x.equals(z)=true ; 4、 一致性:如果参与比较的对象没任何改变,则对象比较的结果也不应该有任何改变; 5、非空性:任何非空的引用值X,x.equals(null)的返回值一定为false 。 ==: == 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指相同一个对象。比较的是真正意义上的指针操作。 1、比较的是操作符两端的操作数是否是同一个对象。 2、两边的操作数必须是同一类型的(可以是父子类之间)才能编译通过。 3、比较的是地址,如果是具体的阿拉伯数字的比较,值相等则为true,如: int a=10 与 long b=10L 与 double c=10.0都是相同的(为true),因为他们都指向地址为10的堆。 equals: equals用来比较的是两个对象的内容是否相等,由于所有的类都是继承自java.lang.Object类的,所以适用于所有对象,如果没有对该方法进行覆盖的话,调用的仍然是Object类中的方法,而Object中的equals方法返回的却是==的判断。 String s="abce"是一种非常特殊的形式,和new 有本质的区别。它是java中唯一不需要new 就可以产生对象的途径。 以String s="abce";形式赋值在java中叫直接量,它是在常量池中而不是象new一样放在压缩堆中。这种形式的字符串,在JVM内部发生字符串拘留,即当声明这样的一个字符串后,JVM会在常量池中先查找有有没有一个值为"abcd"的对象。 如果有,就会把它赋给当前引用.即原来那个引用和现在这个引用指点向了同一对象,如果没有,则在常量池中新创建一个“abcd"”,下一次如果有Strings1="abcd";又会将s1指向“abcd”这个对象,即以这形式声明的字符串,只要值相等,任何多个引用都指向同一对象。 而String s=new String("abcd”);和其它任何对象一样.每调用一次就产生一个对象,只要它们调用。 也可以这么理解:String str="hello”;先在内存中找是不是有“hello”这个对象,如果有,就让str指向那个“hello”。 如果内存里没有"hello",就创建一个新的对象保存"hello”.String str=new String(“hello")就是不管内存里是不是已经有"hello"这个对象,都新建一个对象保存"hello"。
String常用方法
自动装箱和拆箱 自动装箱:基本数据类型->包装类(包装类的valueOf来转化的,-128~127,在的话在Integer缓存的数组当中拿到对应的Integer对象返回,在这个里面的话就相等,不在这个范围里面,就会new一个Integer对象)
Integer引用数据类型,比较地址值是否相同
自动拆箱:包装类->基本数据类型
StringBuilder的常用方法
String-> StringBuffer/StringBuilder
1 2 3 4 String s = "hello" ;StringBuffer buffer = new StringBuffer (s);
String 和 StringBuilder、StringBuffer 的区别?
String:String 的值被创建后不能修改,任何对 String 的修改都会引发新的 String 对象的生成。
StringBuffer:跟 String 类似,但是值可以被修改,使用 synchronized 来保证线程安全。
StringBuilder:StringBuffer 的非线程安全版本,性能上更高一些
第六部分:异常 try catch 直接处理
throws 把异常抛出,让调用者来处理
自定义异常 1 2 3 4 5 6 7 8 public class MyException extends Exception { public MyException (String msg) { super (msg); } } throw new MyException ("编译时异常" );
异常的作用:
可以帮我们获得具体的错误原因
可以让方法调用方知道错误的地方
第七部分:集合 List List集合特点
有索引
可以存储重复元素
元素存入的顺序和实际存储的顺序相同
ArrayList常用方法
遍历方式
1 String[] strings = arrayList.toArray(new String [0 ]);
后面是new什么类型的返回什么样的数组
集合遍历四种形式
for循环遍历
迭代器遍历
foreach遍历
转化为数组再遍历
LinkedList常用方法
遍历同ArrayList
ArrayList和LinkedList有什么区别? ArrayList数组:查找快,增删慢
LinkedList链表:相反
(1) 数据结构不同
ArrayList基于数组实现
LinkedList基于双向链表实现
(2) 多数情况下,ArrayList更利于查找,LinkedList更利于增删
ArrayList基于数组实现,get(int index)可以直接通过数组下标获取,时间复杂度是O(1);LinkedList基于链表实现,get(int index)需要遍历链表,时间复杂度是O(n);当然,get(E element)这种查找,两种集合都需要遍历,时间复杂度都是O(n)。
ArrayList增删如果是数组末尾的位置,直接插入或者删除就可以了,但是如果插入中间的位置,就需要把插入位置后的元素都向前或者向后移动,甚至还有可能触发扩容;双向链表的插入和删除只需要改变前驱节点、后继节点和插入节点的指向就行了,不需要移动元素。
注意,这个地方可能会出陷阱,LinkedList更利于增删更多是体现在平均步长上,不是体现在时间复杂度上,二者增删的时间复杂度都是O(n)
(3) 是否支持随机访问
ArrayList基于数组,所以它可以根据下标查找,支持随机访问,当然,它也实现了RandmoAccess 接口,这个接口只是用来标识是否支持随机访问。
LinkedList基于链表,所以它没法根据序号直接获取元素,它没有实现RandmoAccess 接口,标记不支持随机访问。
(4) 内存占用,ArrayList基于数组,是一块连续的内存空间,LinkedList基于链表,内存空间不连续,它们在空间占用上都有一些额外的消耗:
ArrayList是预先定义好的数组,可能会有空的内存空间,存在一定空间浪费
LinkedList每个节点,需要存储前驱和后继,所以每个节点会占用更多的空间
Set Set集合的特点 不存储重复值
没有索引
不按顺序存储,随机存储
HashSet集合的特点
底层数据结构是哈希表
存储元素和遍历元素顺序可能不一样
没有索引
不存在重复元素
HashSet集合的常用方法
HashSet集合的遍历 转为数组
迭代器
foreach
Map
key有了之后,然后再添加,会覆盖前面的设置value
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Map<String, String> map = new HashMap <>(); map.put("1" ,"k" ); map.put("2" ,"3" ); HashMap<String,String> mm = new HashMap <>(); map.put("1" ,"k" ); map.put("2" ,"z" ); map.put("3" ,"y" ); String s1 = map.put("1" , "康" );System.out.println("s1" +s1); String s = map.get("1" );System.out.println("s = " + s); String remove = map.remove("1" );System.out.println("remove = " + remove); if (map.containsKey("1" )){ String s1 = mm.get("1" ); System.out.println("s1 = " + s1); } mm.clear();
map集合的遍历
equals和hashCode重写的话,属性值相同就相同,就是同一个对象
不重写的话,比较的是地址值
第八部分:泛型 泛型类 创建子类的时候可以指定
泛型方法 方法调用时可以指定
1 2 3 public static <T> T test (T t) { return t; }
向上转型
1 public static void test (List<? extends Student>)
只能传入Student类本身和Student类的子类
向下转型
1 public static void test2 (List<? super Student>)
只能传入泛型为Student类本身和Student类的父类
泛型上限是在定义类可以使用但是?用E来代替
泛型下限是在定义方法时常使用
第九部分:IO 建对象 绝对路径:C:\Users\康\Desktop\git\1.txt
相对路径:1.txt
常用方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void main (String[] args) throws IOException { File file = new File ("D:\\kzy\\1.txt" ); boolean newFile = file.createNewFile(); System.out.println("newFile = " + newFile); File dir = new File ("D:\\kzy\\2" ); boolean newFile1 = file.mkdir(); System.out.println("newFile1 = " + newFile1); File file3 = new File ("D:\\kzy\\1\\2" ); boolean a = file3.mkdirs(); System.out.println("a = " + a); }
第十部分:递归 一般循环和递归都能解决,用循环来解决。递归可能导致栈溢出
求阶乘 1 2 3 4 5 6 7 8 private static int jiecheng (int i) { if (i==1 ) { return 1 ; } return i*jiecheng(i-1 ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public static void deleteFile (File file) { File[] files = file.listFiles(); if (files!=null ){ for (File file1 : files) { if (file1.isFile()) { file1.delete(); } else if (file1.isDirectory()){ { deleteFile(file1); file1.delete(); } } } }
第十一部分:IO流 IO流的分类
字节输入流 创建对象
1 2 3 4 5 6 FileInputStream fileInputStream = new FileInputStream ("D:\\kzy\\1.txt" );File file = new File ("D:\\kzy\\1.txt" );FileInputStream fileInputStream1 = new FileInputStream (file);System.out.println("fileInputStream1 = " + fileInputStream1);
读取fileInputStream 对象
一次读取一个字节数据
1 2 3 4 5 6 7 FileInputStream fileInputStream = new FileInputStream ("D:\\kzy\\1.txt" );int read = fileInputStream.read();sout(read); fileInputStream.close();
一次读取一个字节数组
1 2 3 4 5 6 byte [] bytes = new byte [5 ];int len = fileInputStream.read(bytes); String s = new String (bytes,0 ,len);System.out.println("s = " + s); fileInputStream.close();
1 2 3 4 5 6 7 8 9 10 FileInputStream fileInputStream = new FileInputStream ("D:\\kzy\\1.txt" ); byte [] bytes = new byte [1024 *2 ]; int len; while ((len=fileInputStream.read(bytes))!=-1 ){ System.out.println(new String (bytes,0 ,len));
资源释放的写法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 FileInputStream fileInputStream = null ;try { fileInputStream = new FileInputStream ("D:\\kzy\\1.txt" ); byte [] bytes = new byte [1024 *2 ]; int len; while ((len=fileInputStream.read(bytes))!=-1 ){ System.out.println(new String (bytes,0 ,len)); } } catch (IOException e) { e.printStackTrace(); } finally { if (fileInputStream != null ) { try { fileInputStream.close(); } catch (IOException e) { e.printStackTrace(); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private static void exceptionq () { FileInputStream fileInputStream = null ; try { fileInputStream = new FileInputStream ("D:\\kzy\\1.txt" ); byte [] bytes = new byte [1024 *2 ]; int len; while ((len=fileInputStream.read(bytes))!=-1 ){ System.out.println(new String (bytes,0 ,len)); } } catch (IOException e) { e.printStackTrace(); } }
字节流,复制文件
字符流,写文本什么的
字节输出流 输出流FileOutputStream写对象
1 2 3 4 5 6 7 public static void main(String[] args) throws IOException { //输出流写对象 FileOutputStream fileOutputStream = new FileOutputStream("D:\\kzy\\1.txt"); byte[] bytes = "123".getBytes(); fileOutputStream.write(bytes); }
文件续写 1 2 3 4 5 6 FileOutputStream fis = new FileOutputStream ("D:\\kzy\\1.txt" ,true );byte [] bytes = "123" .getBytes();fis.write(bytes);
文件复制 首先在目标文件夹中建立一个和原文件一样名字的文件,然后通过输入流读原文件,输出流写文件到目标文件中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class Demo2 { public static void main (String[] args) throws IOException { File srcFile = new File ("D:\\kzy\\1697274314932.jpg" ); File destDir = new File ("D:\\kzy\\c" ); copyFile(srcFile, destDir); } public static void copyFile (File srcFile, File destDir) throws IOException { File file = new File (destDir, srcFile.getName()); FileInputStream fileInputStream = new FileInputStream (srcFile); FileOutputStream fileOutputStream = new FileOutputStream (file); byte [] bytes = new byte [1024 * 2 ]; int len; while ((len = fileInputStream.read(bytes)) != -1 ) { fileOutputStream.write(bytes, 0 , len); } } }
文件夹的复制 不考虑有子文件夹
首先在目标文件夹中建立一个和原文件夹一样名字的文件夹,然后遍历原文件夹,获取所有文件,然后通过以上文件复制,将文件复制到对应的文件夹中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 public class Demo3 { public static void main (String[] args) throws IOException { File srcFile = new File ("D:\\kzy\\test1" ); File destDir = new File ("D:\\kzy\\test2" ); copyDir(srcFile,destDir); } public static void copyDir (File srcDir, File destDir) throws IOException { if (!(srcDir.exists() && srcDir.isDirectory())) { throw new RuntimeException ("原文件夹必须存在,并且是文件夹" ); } if (!destDir.exists()&& destDir.isDirectory()) { throw new RuntimeException ("文件夹必须存在" ); } File dir = new File (destDir, srcDir.getName()); dir.mkdirs(); File[] files = srcDir.listFiles(); for (File file : files) { copyFile(file, dir); } } public static void copyFile (File srcFile, File destDir) throws IOException { File file = new File (destDir, srcFile.getName()); FileInputStream fileInputStream = new FileInputStream (srcFile); FileOutputStream fileOutputStream = new FileOutputStream (file); byte [] bytes = new byte [1024 * 2 ]; int len; while ((len = fileInputStream.read(bytes)) != -1 ) { fileOutputStream.write(bytes, 0 , len); } } }
考虑有子文件夹
首先在目标文件夹中建立一个和原文件夹一样名字的文件夹,然后遍历原文件夹,获取所有文件,判断是否是文件夹,是文件夹的话通过递归复制,是文件,直接通过以上文件复制,将文件复制到对应的文件夹中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 public class Demo4 { public static void main (String[] args) throws IOException { File srcFile = new File ("D:\\kzy\\test1" ); File destDir = new File ("D:\\kzy\\test2" ); copyDir(srcFile,destDir); } public static void copyDir (File srcDir, File destDir) throws IOException { if (!(srcDir.exists() && srcDir.isDirectory())) { throw new RuntimeException ("原文件夹必须存在,并且是文件夹" ); } if (!destDir.exists()&& destDir.isDirectory()) { throw new RuntimeException ("文件夹必须存在" ); } File dir = new File (destDir, srcDir.getName()); dir.mkdirs(); File[] files = srcDir.listFiles(); for (File file : files) { if (file.isFile()) { copyFile(file, dir); } else if (file.isDirectory()){ copyDir(file,dir); } } } public static void copyFile (File srcFile, File destDir) throws IOException { File file = new File (destDir, srcFile.getName()); FileInputStream fileInputStream = new FileInputStream (srcFile); FileOutputStream fileOutputStream = new FileOutputStream (file); byte [] bytes = new byte [1024 * 2 ]; int len; while ((len = fileInputStream.read(bytes)) != -1 ) { fileOutputStream.write(bytes, 0 , len); } } }
编码和解码(字节流) 编码和解码方式相同才不会乱码
默认时UTF-8
字符流 当我们读取(写入)的是纯文本的形式时,我们可以用字符流来进行操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class Demo5 { public static void main (String[] args) throws IOException { FileReader fileReader = new FileReader (new File ("D:\\kzy\\test1\\1.txt" )); char [] chars = new char [1024 *2 ]; int len2; while ((len2 = fileReader.read(chars))!=-1 ){ System.out.println("fileReader.read() = " + new String (chars)); } fileReader.close(); } }
字符输出流 write会先将写入的数据放在内存缓冲区,flush或者close时,才会真正写入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 FileWriter fileWriter = new FileWriter (new File ("D:\\kzy\\test1\\1.txt" ));fileWriter.write("你" ); fileWriter.flush(); fileWriter.write("最" ); fileWriter.write("棒" ); char [] chars = "三更草堂" .toCharArray();fileWriter.write(chars); fileWriter.flush(); fileWriter.write("三更草堂" ); fileWriter.close();
复制最好使用字节流,可以复制任意的。字符流只能复制文本
字符流会读取字符数组。字节流会读取字节数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class Demo7 { public static void main (String[] args) throws IOException { File srcFile = new File ("D:\\kzy\\1.txt" ); File destDir = new File ("D:\\kzy\\c" ); copyFile(srcFile, destDir); } public static void copyFile (File srcFile, File destDir) throws IOException { File file = new File (destDir, srcFile.getName()); FileReader fr = new FileReader (srcFile); FileWriter fw = new FileWriter (file); char [] chars = new char [1024 * 2 ]; int len; while ((len = fr.read(chars)) != -1 ) { fw.write(chars, 0 , len); } fr.close(); fw.close(); } }
字符流编码的设置
高效缓冲流 读数据,先将磁盘的部分数据读到内存缓冲区,然后内存直接读取缓冲区的数据,更快。。。借助内存的缓冲区来减少磁盘IO的次数,提高性能
分类
对象创建
特有方法
BufferedRead: readLine() 一次读一行,不包括换行符
BufferedWriter: newLine() 换行符
1 2 3 4 5 6 7 public static void main (String[] args) throws IOException { BufferedReader bufferedReader = new BufferedReader (new FileReader ("D:\\kzy\\test1\\2.txt" )); String len; while ((len=bufferedReader.readLine())!=null ){ System.out.println("bufferedReader.readLine() = " + len); } }
文件内容的复制
1 2 3 4 5 6 7 8 9 10 11 12 13 public static void main (String[] args) throws IOException { BufferedReader bfr = new BufferedReader (new FileReader ("D:\\kzy\\test1\\2.txt" )); BufferedWriter bfw = new BufferedWriter (new FileWriter ("D:\\kzy\\test1\\1.txt" ,true )); String len; while ((len=bfr.readLine())!=null ){ bfw.write(len); bfw.newLine(); } bfr.close(); bfw.close(); }
跟着三更学JAVA-函数式编程 优点
Lambda表达式 不注重方法名,只注重参数和所进行的操作
1 2 3 4 5 6 7 8 9 10 11 new Thread (() -> { System.out.println("线程被启动了" ); }).start(); new Thread (new Runnable () { @Override public void run () { System.out.println("又被启动了" ); } }).start(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int cal = cal((left, right) -> left + right); System.out.println("cal = " + cal); } public static int cal (IntBinaryOperator intBinaryOperator) { int a=10 ; int b=20 ; return intBinaryOperator.applyAsInt(a,b); }
优化
参数类型可以省略
方法体内只有一句代码时大括号的return和唯一依据代码的分号可以省略
方法只有一个参数时小括号可以省略
Stream流 更方便的对集合和数组进行操作
创建对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private static void test02 () { ArrayList<Integer> arr = new ArrayList <>(); arr.add(1 ); arr.add(4 ); arr.add(3 ); arr.add(2 ); Stream<Integer> stream = arr.stream(); stream.distinct() .filter(integer -> integer>2 ) .forEach(System.out::println); }
1 2 3 4 5 6 7 8 9 10 11 12 private static void test01 () { Integer[] arr = {1 , 2 , 3 , 4 , 6 }; Stream<Integer> stream = Arrays.stream(arr); stream.distinct() .filter(integer -> integer>2 ) .forEach(System.out::println); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private static void test03 () { HashMap<String,Integer> map = new HashMap <>(); map.put("1" ,2 ); map.put("2" ,3 ); map.put("3" ,4 ); Stream<Map.Entry<String, Integer>> stream = map.entrySet().stream(); stream.filter(entry -> entry.getValue()>2 ) .forEach(entry -> System.out.println(entry.getKey()+entry.getValue())); }
中间操作 distinct 去重,去掉相同的元素。如果是判断对象是否相同,要重写equals方法,否则用的是==来比较,比较的是地址值。应该比较属性值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private static void test05 () { ArrayList<Integer> arr = new ArrayList <>(); arr.add(1 ); arr.add(4 ); arr.add(3 ); arr.add(2 ); arr.add(2 ); arr.add(2 ); System.out.println(arr); Stream<Integer> stream = arr.stream(); stream.distinct() .forEach(System.out::println); }
filter 过滤(筛选);可以对流中的元素进行条件过滤,符合条件的数据继续存在流中
例子:查询年龄大于20的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private static void test04 () { HashMap<String,Integer> map = new HashMap <>(); map.put("康志远" ,20 ); map.put("翟龙浩" ,21 ); map.put("魏晓静" ,19 ); Stream<Map.Entry<String, Integer>> stream = map.entrySet().stream(); stream.filter(new Predicate <Map.Entry<String, Integer>>() { @Override public boolean test (Map.Entry<String, Integer> entry) { return entry.getValue()>19 ; } }).forEach(System.out::println); }
map 可以对流进行类型转换和计算
将流中的Person转为String流获取所有人的名字和每个人的年龄加一
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private static void test06 () { ArrayList<Person> arrayList = new ArrayList <>(); arrayList.add(new Person ("康志远" ,20 )); arrayList.add(new Person ("翟龙浩" ,21 )); arrayList.add(new Person ("康之源" ,18 )); arrayList.stream() .map(person -> person.getName()) .forEach(s -> System.out.println(s)); arrayList.stream() .map(person -> person.getAge()) .map(age->age+1 ) .forEach(System.out::println); }
sorted 对流中的元素进行排序,
注意:需要对排序的对象进行implements Comparable,并重写compareTo方法
1 2 3 4 @Override public int compareTo (Person o) { return this .getAge()-o.getAge(); }
或者直接实现
1 2 3 4 5 6 .sorted(new Comparator <Person>() { @Override public int compare (Person o1, Person o2) { return o1.getAge()-o2.getAge(); } })
limit 设置最大流,超出的最终被抛弃
例子:进行降序处理,并去重,然后打印出年龄最大的三位
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 private static void test08 () { ArrayList<Person> arrayList = new ArrayList <>(); arrayList.add(new Person ("康志远" ,20 )); arrayList.add(new Person ("翟龙浩" ,21 )); arrayList.add(new Person ("康2源" ,18 )); arrayList.add(new Person ("康3源" ,20 )); arrayList.add(new Person ("康4源" ,13 )); arrayList.add(new Person ("康5源" ,14 )); arrayList.add(new Person ("康6源" ,24 )); arrayList.add(new Person ("康7源" ,19 )); arrayList.stream() .distinct() .sorted(new Comparator <Person>() { @Override public int compare (Person o1, Person o2) { return o2.getAge()-o1.getAge(); } }) .limit(3 ) .forEach(System.out::println); }
skip 跳过前n个元素,并返回剩下的元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 private static void test09 () { ArrayList<Person> arrayList = new ArrayList <>(); arrayList.add(new Person ("康志远" ,20 )); arrayList.add(new Person ("翟龙浩" ,21 )); arrayList.add(new Person ("康2源" ,18 )); arrayList.add(new Person ("康3源" ,20 )); arrayList.add(new Person ("康4源" ,13 )); arrayList.add(new Person ("康5源" ,14 )); arrayList.add(new Person ("康6源" ,24 )); arrayList.add(new Person ("康7源" ,19 )); arrayList.stream() .distinct() .sorted(new Comparator <Person>() { @Override public int compare (Person o1, Person o2) { return o2.getAge()-o1.getAge(); } }) .skip(1 ) .forEach(System.out::println); }
flatMap map只能把一个对象转化成另一个对象来作为流中的元素,而flatMap可以将一个对象转化为多个对象来体现
把一个元素转化为多个元素。比如一个类里面有一个集合元素,flatMap先将这个类中的集合,将他转化为新的流
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class Person { String name; Integer age; List<Person> list; } private static void test10 () { ArrayList<Person> arrayList = new ArrayList <>(); arrayList.add(new Person ("康志远" , 20 )); arrayList.add(new Person ("翟龙浩" , 21 )); arrayList.add(new Person ("康2源" , 18 )); arrayList.add(new Person ("康3源" , 20 )); arrayList.add(new Person ("康4源" , 13 )); arrayList.add(new Person ("康5源" , 14 )); arrayList.add(new Person ("康6源" , 24 )); arrayList.add(new Person ("康7源" , 19 )); Person person = new Person (); person.setList(arrayList); arrayList.stream() .distinct() .flatMap((Function<Person, Stream<Person>>) person1 -> { return person1.getList().stream(); }).forEach(new Consumer <Person>() { @Override public void accept (Person o) { System.out.println(o.getName()); } }); }
终结操作 foreach 遍历输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private static void test11 () { ArrayList<Person> arrayList = new ArrayList <>(); arrayList.add(new Person ("康志远" , 20 )); arrayList.add(new Person ("翟龙浩" , 21 )); arrayList.add(new Person ("康之源" , 18 )); arrayList.stream() .map(person -> person.getName()) .forEach(s -> System.out.println(s)); }
count 用来获取数目,注意有返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public static void test12 () { ArrayList<Integer> arr = new ArrayList <>(); arr.add(1 ); arr.add(4 ); arr.add(3 ); arr.add(2 ); arr.add(2 ); arr.add(2 ); System.out.println(arr); Stream<Integer> stream = arr.stream(); long count = stream.distinct() .count(); System.out.println("count = " + count); }
min和max 注意有返回值Optional,一个流完之后,需要在获取另一个流
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private static void test13 () { ArrayList<Integer> arr = new ArrayList <>(); arr.add(1 ); arr.add(4 ); arr.add(3 ); arr.add(2 ); arr.add(2 ); arr.add(2 ); System.out.println(arr); Stream<Integer> stream = arr.stream(); Optional<Integer> max = stream .max(new Comparator <Integer>() { @Override public int compare (Integer o1, Integer o2) { return o1 - o2; } }); Stream<Integer> stream2 = arr.stream(); Optional<Integer> min = stream2 .min(new Comparator <Integer>() { @Override public int compare (Integer o1, Integer o2) { return o1 - o2; } }); System.out.println("max.get() = " + max.get()); System.out.println("min.get() = " + min.get()); }
collect 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private static ArrayList<Person> arrayList; static { arrayList = new ArrayList <>(); arrayList.add(new Person ("康志远" , 20 )); arrayList.add(new Person ("翟龙浩" , 21 )); arrayList.add(new Person ("康2源" , 18 )); arrayList.add(new Person ("康3源" , 20 )); arrayList.add(new Person ("康4源" , 13 )); arrayList.add(new Person ("康5源" , 14 )); arrayList.add(new Person ("康6源" , 20 )); arrayList.add(new Person ("康7源" , 19 )); }
List集合 1 2 3 4 5 6 7 8 9 private static void test14 () { Stream<Person> stream = arrayList.stream(); List<String> names = stream.map(person -> person.getName()) .collect(Collectors.toList()); System.out.println(names); }
Set集合 可以去重
1 2 3 4 5 6 7 8 9 private static void test15 () { Stream<Person> stream = arrayList.stream(); Set<String> names = stream.map(person -> person.getName()) .collect(Collectors.toSet()); System.out.println(names); }
Map集合 需要new两个Function,一个是key,一个是value
1 2 3 4 5 6 7 8 private static void test16 () { Stream<Person> stream = arrayList.stream(); Map<String, Integer> collects = stream.collect(Collectors.toMap(person -> person.getName(), person -> person.getAge())); System.out.println(collects); }
anyMatch 查询是否有任意一个元素符合匹配条件,有一个符合就为true
1 2 3 4 5 6 7 8 private static void test01 () { boolean b = arrayList.stream() .anyMatch(person -> person.getAge() > 20 ); System.out.println("b = " + b); }
allMatch 查询是否所有元素符合匹配条件,所有符合就为true,有不符合的就为false
1 2 3 4 5 6 7 8 private static void test02 () { boolean b = arrayList.stream() .allMatch(person -> person.getAge() > 20 ); System.out.println("b = " + b); }
noneMatch 查询是否所有元素都不符合匹配条件,都不符合就为true,有符合的就为false
1 2 3 4 5 6 7 8 private static void test03 () { boolean b = arrayList.stream() .noneMatch(person -> person.getAge() > 23 ); System.out.println("b = " + b); }
findAny 获取任意一个符合条件的元素,不一定是第一个元素
1 2 3 4 5 6 7 8 9 10 11 private static void test04 () { Optional<Person> persons = arrayList.stream() .filter(person -> person.getAge() > 19 ) .findAny(); persons.ifPresent(person -> System.out.println("person = " + person.getName())); }
findFirst 查找第一个元素
1 2 3 4 5 6 7 8 9 private static void test05 () { Optional<Person> person = arrayList.stream() .sorted((o1, o2) -> o1.getAge() - o2.getAge()) .findFirst(); person.ifPresent(person1 -> System.out.println("person1 = " + person1.getName())); }
reduce
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private static void test06 () { Integer sum = arrayList.stream() .map(person -> person.getAge()) .reduce(0 , new BinaryOperator <Integer>() { @Override public Integer apply (Integer result, Integer integer) { return result + integer; } }); System.out.println("sum = " + sum); }
1 2 3 4 5 6 7 8 9 private static void test07 () { Integer max = arrayList.stream() .map(person -> person.getAge()) .reduce(Integer.MIN_VALUE, (result, element) -> result < element ? element : result); System.out.println("max = " + max); }
1 2 3 4 5 6 7 8 9 private static void test08 () { Optional<Integer> min = arrayList.stream() .map(person -> person.getAge()) .reduce((result, element) -> result > element ? element : result); System.out.println("min = " + min); }
注意事项
Optional 4.1概述 编写代码最多的是空指针异常,所以我们需要做各种非空判断
利用Optional来处理是否为空
4.2使用 4.2.1创建对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public static void main (String[] args) { Optional<List<Person>> list = getList(); list.ifPresent(people -> System.out.println("people = " + people)); Person person = new Person (); Optional<Person> person1 = Optional.of(person); person1.ifPresent(person2 -> System.out.println("person2 = " + person2)); } private static Optional<List<Person>> getList () { ArrayList<Person> arrayList = new ArrayList <>(); arrayList.add(new Person ("康志远" , 20 )); arrayList.add(new Person ("翟龙浩" , 21 )); arrayList.add(new Person ("康2源" , 18 )); arrayList.add(new Person ("康3源" , 20 )); arrayList.add(new Person ("康4源" , 13 )); arrayList.add(new Person ("康5源" , 14 )); arrayList.add(new Person ("康6源" , 24 )); arrayList.add(new Person ("康7源" , 19 )); return Optional.ofNullable(arrayList); } }
4.2.1安全消费值 1 list.ifPresent(people -> System.out.println("people = " + people));
4.2.2安全的获取值 get 获取值
orElseGet 如果有值返回值,没值返回设定的默认值
1 2 3 4 Optional<List<Person>> list = getList(); List<Person> personList = list.orElseGet(() -> null ); System.out.println("personList = " + personList);
orElseThrow 如果有值返回值,没值返回设定异常类型提示信息
1 2 3 List<Person> personList = list.orElseThrow(() -> new RuntimeException ("空指针" )); System.out.println("personList = " + personList);
4.2.3过滤 我们可以使用这个方法对数据进行过滤,如果原本有数据,但是不符合判断,也会变成一个无数据的Optional对象
1 2 3 4 5 6 7 8 Optional<Person> list = Optional.ofNullable(getList()); list.filter(new Predicate <Person>() { @Override public boolean test (Person person) { return person.getAge()>18 ; } }).ifPresent(person -> System.out.println("person = " + person.getName()));
4.2.4判断 判断是否存在数据进行判断,如果为空fasle不为空true
isPersent()
4.2.5数据转换 和map、flatMap相似
函数式接口 5.1 概述 只有一个抽象方法 的接口我们称之为函数接口。
JDK的函数式接口都加上了**@FunctionalInterface** 注解进行标识。但是无论是否加上该注解只要接口中只有一个抽象方法,都是函数式接口。
5.2 常见函数式接口
Consumer 消费接口
根据其中抽象方法的参数列表和返回值类型知道,我们可以在方法中对传入的参数进行消费。
Function 计算转换接口
根据其中抽象方法的参数列表和返回值类型知道,我们可以在方法中对传入的参数计算或转换,把结果返回
Predicate 判断接口
根据其中抽象方法的参数列表和返回值类型知道,我们可以在方法中对传入的参数条件判断,返回判断结果
Supplier 生产型接口
根据其中抽象方法的参数列表和返回值类型知道,我们可以在方法中创建对象,把创建好的对象返回
5.3 常用的默认方法
and
我们在使用Predicate接口时候可能需要进行判断条件的拼接。而and方法相当于是使用&&来拼接两个判断条件
例如:
打印作家中年龄大于17并且姓名的长度大于1的作家。
1 2 3 4 5 6 7 8 9 10 11 12 13 List<Author> authors = getAuthors(); Stream<Author> authorStream = authors.stream(); authorStream.filter(new Predicate <Author>() { @Override public boolean test (Author author) { return author.getAge()>17 ; } }.and(new Predicate <Author>() { @Override public boolean test (Author author) { return author.getName().length()>1 ; } })).forEach(author -> System.out.println(author));
or
我们在使用Predicate接口时候可能需要进行判断条件的拼接。而or方法相当于是使用||来拼接两个判断条件。
例如:
打印作家中年龄大于17或者姓名的长度小于2的作家。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 List<Author> authors = getAuthors(); authors.stream() .filter(new Predicate <Author>() { @Override public boolean test (Author author) { return author.getAge()>17 ; } }.or(new Predicate <Author>() { @Override public boolean test (Author author) { return author.getName().length()<2 ; } })).forEach(author -> System.out.println(author.getName()));
negate
Predicate接口中的方法。negate方法相当于是在判断添加前面加了个! 表示取反
例如:
打印作家中年龄不大于17的作家。
1 2 3 4 5 6 7 8 9 List<Author> authors = getAuthors(); authors.stream() .filter(new Predicate <Author>() { @Override public boolean test (Author author) { return author.getAge()>17 ; } }.negate()).forEach(author -> System.out.println(author.getAge()));
方法引用 我们在使用lambda时,如果方法体中只有一个方法的调用的话(包括构造方法),我们可以用方法引用进一步简化代码。
6.1 推荐用法 我们在使用lambda时不需要考虑什么时候用方法引用,用哪种方法引用,方法引用的格式是什么。我们只需要在写完lambda方法发现方法体只有一行代码,并且是方法的调用时使用快捷键尝试是否能够转换成方法引用即可。
当我们方法引用使用的多了慢慢的也可以直接写出方法引用。
6.2 基本格式 类名或者对象名::方法名
6.3 语法详解(了解) 6.3.1 引用类的静态方法 其实就是引用类的静态方法
格式 使用前提 如果我们在重写方法的时候,方法体中只有一行代码 ,并且这行代码是调用了某个类的静态方法 ,并且我们把要重写的抽象方法中所有的参数都按照顺序传入了这个静态方法中 ,这个时候我们就可以引用类的静态方法。
例如:
如下代码就可以用方法引用进行简化
1 2 3 4 5 6 List<Author> authors = getAuthors(); Stream<Author> authorStream = authors.stream(); authorStream.map(author -> author.getAge()) .map(age->String.valueOf(age));
注意,如果我们所重写的方法是没有参数的,调用的方法也是没有参数的也相当于符合以上规则。
优化后如下:
1 2 3 4 5 6 List<Author> authors = getAuthors(); Stream<Author> authorStream = authors.stream(); authorStream.map(author -> author.getAge()) .map(String::valueOf);
6.3.2 引用对象的实例方法 格式 使用前提 如果我们在重写方法的时候,方法体中只有一行代码 ,并且这行代码是调用了某个对象的成员方法 ,并且我们把要重写的抽象方法中所有的参数都按照顺序传入了这个成员方法中 ,这个时候我们就可以引用对象的实例方法
例如:
1 2 3 4 5 6 List<Author> authors = getAuthors(); Stream<Author> authorStream = authors.stream(); StringBuilder sb = new StringBuilder ();authorStream.map(author -> author.getName()) .forEach(name->sb.append(name));
优化后:
1 2 3 4 5 6 List<Author> authors = getAuthors(); Stream<Author> authorStream = authors.stream(); StringBuilder sb = new StringBuilder ();authorStream.map(author -> author.getName()) .forEach(sb::append);
6.3.4 引用类的实例方法 格式 使用前提 如果我们在重写方法的时候,方法体中只有一行代码 ,并且这行代码是调用了第一个参数的成员方法 ,并且我们把要重写的抽象方法中剩余的所有的参数都按照顺序传入了这个成员方法中 ,这个时候我们就可以引用类的实例方法。
例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 interface UseString { String use (String str,int start,int length) ; } public static String subAuthorName (String str, UseString useString) { int start = 0 ; int length = 1 ; return useString.use(str,start,length); } public static void main (String[] args) { subAuthorName("三更草堂" , new UseString () { @Override public String use (String str, int start, int length) { return str.substring(start,length); } }); }
优化后如下:
1 2 3 4 5 public static void main (String[] args) { subAuthorName("三更草堂" , String::substring); }
6.3.5 构造器引用 如果方法体中的一行代码是构造器的话就可以使用构造器引用。
格式 使用前提 如果我们在重写方法的时候,方法体中只有一行代码 ,并且这行代码是调用了某个类的构造方法 ,并且我们把要重写的抽象方法中的所有的参数都按照顺序传入了这个构造方法中 ,这个时候我们就可以引用构造器。
例如:
1 2 3 4 5 6 List<Author> authors = getAuthors(); authors.stream() .map(author -> author.getName()) .map(name->new StringBuilder (name)) .map(sb->sb.append("-三更" ).toString()) .forEach(str-> System.out.println(str));
优化后:
1 2 3 4 5 6 List<Author> authors = getAuthors(); authors.stream() .map(author -> author.getName()) .map(StringBuilder::new ) .map(sb->sb.append("-三更" ).toString()) .forEach(str-> System.out.println(str));
高级用法 基本数据类型优化 我们之前用到的很多Stream的方法由于都使用了泛型。所以涉及到的参数和返回值都是引用数据类型。
即使我们操作的是整数小数,但是实际用的都是他们的包装类。JDK5中引入的自动装箱和自动拆箱让我们在使用对应的包装类时就好像使用基本数据类型一样方便。但是你一定要知道装箱和拆箱肯定是要消耗时间的。虽然这个时间消耗很下。但是在大量的数据不断的重复装箱拆箱的时候,你就不能无视这个时间损耗了。
所以为了让我们能够对这部分的时间消耗进行优化。Stream还提供了很多专门针对基本数据类型的方法。
例如:mapToInt,mapToLong,mapToDouble,flatMapToInt,flatMapToDouble等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private static void test27 () { List<Author> authors = getAuthors(); authors.stream() .map(author -> author.getAge()) .map(age -> age + 10 ) .filter(age->age>18 ) .map(age->age+2 ) .forEach(System.out::println); authors.stream() .mapToInt(author -> author.getAge()) .map(age -> age + 10 ) .filter(age->age>18 ) .map(age->age+2 ) .forEach(System.out::println); }
并行流 当流中有大量元素时,我们可以使用并行流去提高操作的效率。其实并行流就是把任务分配给多个线程去完全。如果我们自己去用代码实现的话其实会非常的复杂,并且要求你对并发编程有足够的理解和认识。而如果我们使用Stream的话,我们只需要修改一个方法的调用就可以使用并行流来帮我们实现,从而提高效率。
parallel方法可以把串行流转换成并行流。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 private static void test28 () { Stream<Integer> stream = Stream.of(1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ); Integer sum = stream.parallel() .peek(new Consumer <Integer>() { @Override public void accept (Integer num) { System.out.println(num+Thread.currentThread().getName()); } }) .filter(num -> num > 5 ) .reduce((result, ele) -> result + ele) .get(); System.out.println(sum); }
也可以通过parallelStream直接获取并行流对象。
1 2 3 4 5 6 7 List<Author> authors = getAuthors(); authors.parallelStream() .map(author -> author.getAge()) .map(age -> age + 10 ) .filter(age->age>18 ) .map(age->age+2 ) .forEach(System.out::println);
跟着三更学JAVA-多线程 1.1实现多线程方式一:继承Thread类【应用】
方法介绍
方法名
说明
void run()
在线程开启后,此方法将被调用执行
void start()
使此线程开始执行,Java虚拟机会调用run方法()
实现步骤
定义一个类MyThread继承Thread类
在MyThread类中重写run()方法
创建MyThread类的对象
启动线程(必须用start()方法)
代码演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class MyThread extends Thread { @Override public void run () { for (int i=0 ; i<100 ; i++) { System.out.println(i); } } } public class MyThreadDemo { public static void main (String[] args) { MyThread my1 = new MyThread (); MyThread my2 = new MyThread (); my1.start(); my2.start(); } }
两个小问题
1.2实现多线程方式二:实现Runnable接口【应用】
1.3实现多线程方式三:实现Callable接口【应用】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class Thread03 implements Callable <Integer> { private int n; public Thread03 (int i) { } public int getN () { return n; } public void setN (int n) { this .n = n; } @Override public Integer call () throws Exception { int sum = 0 ; for (int i = 0 ; i < n; i++) { sum+=i; } return sum; } } Callable<Integer> thread03 = new Thread03 (100 ); FutureTask<Integer> f1 = new FutureTask <>(thread03); new Thread (f1).start(); Integer integer = f1.get(); System.out.println("integer = " + integer);
Thread相关的API
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Test04 { public static void main (String[] args) { Thread t1 = new Thread04 (); t1.getName(); t1.start(); Thread thread = Thread.currentThread(); thread.setName("牛逼" ); System.out.println("thread = " + thread.getName()); for (int i = 0 ; i < 5 ; i++) { System.out.println(thread.getName()+"线程输出" +i); } } } public class Thread04 extends Thread { @Override public void run () { Thread thread = Thread.currentThread(); for (int i = 0 ; i < 5 ; i++) { System.out.println(thread.getName()+"执行了 = " + i); } } }
线程安全问题 多个线程同时操作同一个共享资源,并且修改同一个共享资源
两个人同时取钱问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 public class Account { private double money; private String cardId; public double getMoney () { return money; } public void setMoney (double money) { this .money = money; } public String getCardId () { return cardId; } public void setCardId (String cardId) { this .cardId = cardId; } public Account (double money, String cardId) { this .money = money; this .cardId = cardId; } public Account () { } public void drawMoney (double money) { String name = Thread.currentThread().getName(); if (this .money>=money){ System.out.println(name+"来取了" +money+"钱" ); this .money-=money; System.out.println(name+"取钱后剩余" +this .money+"钱" ); } else { System.out.println("余额不足" ); } } } public class DrawThread extends Thread { private Account account; public DrawThread (Account acc,String name) { super (name); this .account = acc; } @Override public void run () { account.drawMoney(200.0 ); } } public class ThreadTest { public static void main (String[] args) { Account account = new Account (1000.0 ,"ICBC-188" ); new DrawThread (account,"小明" ).start(); new DrawThread (account,"小红" ).start(); } }
线程同步(解决线程安全) 让多个线程先后依次访问共享资源,这样就解决了线程安全问题
加锁方案 同步代码块
多个线程要有同一把钥匙来打开一个共享资源
1 2 3 4 5 6 7 8 9 10 11 12 13 public void drawMoney (double money) { String name = Thread.currentThread().getName(); synchronized (this ) { if (this .money>=money){ System.out.println(name+"来取了" +money+"钱" ); this .money-=money; System.out.println(name+"取钱后剩余" +this .money+"钱" ); } else { System.out.println("余额不足" ); } } }
同步方法
Lock锁
定义锁,自己来加锁和解锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class Account { private double money; private String cardId; private final Lock lk = new ReentrantLock (); } public void drawMoney (double money) { String name = Thread.currentThread().getName(); lk.lock(); try { if (this .money>=money){ System.out.println(name+"来取了" +money+"钱" ); this .money-=money; System.out.println(name+"取钱后剩余" +this .money+"钱" ); } else { System.out.println("余额不足" ); } } catch (Exception e) { e.printStackTrace(); } finally { lk.unlock(); } }
线程池 可以复用线程的技术,不会因为线程过多而导致线程瘫痪。可以创建几个线程来执行多个任务
线程池可以控制线程的数量和任务的数量(不会导致瘫痪),让线程去反复的去处理任务.
任务队列里面都是实现了Runnable和Callable的对象,因为是把他们交给线程池
ThreadPoolExecutor创建线程池
线程池的注意事项
临时线程什么时候创建
新任务提交时核心线程都在忙,并且任务队列都满了,并且还可以在创建临时线程,此时才可以创建临时线程
什么时候会开始拒绝新任务
核心线程和临时线程都在工作,并且任务队列也满了,会根据拒绝策略去拒绝新任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import java.util.Collection;import java.util.Iterator;import java.util.concurrent.*;public class Pool { public static void main (String[] args) { ExecutorService executorService = new ThreadPoolExecutor (3 , 5 , 5 , TimeUnit.HOURS, new LinkedBlockingDeque <>(5 ),Executors.defaultThreadFactory(),new ThreadPoolExecutor .AbortPolicy()); } }
线程池处理Runnable对象
拒绝策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 package pool;import java.util.Collection;import java.util.Iterator;import java.util.concurrent.*;public class Pool { public static void main (String[] args) { ExecutorService pool = new ThreadPoolExecutor (3 , 5 , 5 , TimeUnit.HOURS, new LinkedBlockingDeque <>(4 ),Executors.defaultThreadFactory(),new ThreadPoolExecutor .CallerRunsPolicy()); Runnable runnable = new RunnableP (); pool.execute(runnable); pool.execute(runnable); pool.execute(runnable); pool.execute(runnable); pool.execute(runnable); pool.execute(runnable); pool.execute(runnable); pool.execute(runnable); pool.execute(runnable); pool.execute(runnable); } } "C:\Program Files\Java\jdk1.8.0_131\bin\java.exe" "-javaagent:D:\JavaP\idea\IntelliJ IDEA 2019.2.4\lib\idea_rt.jar=61317:D:\JavaP\idea\IntelliJ IDEA 2019.2.4\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_131\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\access-bridge-64.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\cldrdata.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\dnsns.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\jaccess.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\jfxrt.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\localedata.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\nashorn.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\sunec.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\sunjce_provider.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\sunmscapi.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\sunpkcs11.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\ext\zipfs.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\javaws.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\jce.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\jfr.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\jfxswt.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\jsse.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\management-agent.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\plugin.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\resources.jar;C:\Program Files\Java\jdk1.8.0_131\jre\lib\rt.jar;D:\JavaP\IdeaProjects\sangengtest\out\production\day09" Thread[pool-1 -thread-1 ,5 ,main]线程打印6666 Thread[main,5 ,main]线程打印6666 Thread[pool-1 -thread-3 ,5 ,main]线程打印6666 Thread[pool-1 -thread-2 ,5 ,main]线程打印6666 Thread[pool-1 -thread-5 ,5 ,main]线程打印6666 Thread[pool-1 -thread-4 ,5 ,main]线程打印6666
线程池处理Callable对象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package pool;import java.util.concurrent.Callable;public class CallableP implements Callable <String> { private int a; public CallableP (int a) { this .a = a; } @Override public String call () throws Exception { int sum=0 ; for (int i = 0 ; i < a; i++) { sum = i; } return Thread.currentThread()+"he为" +sum; } } package pool;import java.util.concurrent.*;public class Pool2 { public static void main (String[] args) throws ExecutionException, InterruptedException { ExecutorService pool = new ThreadPoolExecutor (3 , 5 , 5 , TimeUnit.HOURS, new LinkedBlockingDeque <>(4 ), Executors.defaultThreadFactory(), new ThreadPoolExecutor .CallerRunsPolicy()); CallableP callableP = new CallableP (5 ); Future<String> submit1 = pool.submit(callableP); Future<String> submit2 = pool.submit(callableP); Future<String> submit3 = pool.submit(callableP); Future<String> submit4 = pool.submit(callableP); System.out.println("submit1 = " + submit1.get()); System.out.println("submit2 = " + submit2.get()); System.out.println("submit3 = " + submit3.get()); System.out.println("submit4 = " + submit4.get()); } }
Executors创建线程池
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 CallableP callableP = new CallableP (13 ); ExecutorService pool = Executors.newFixedThreadPool(3 ); Future<String> submit1 = pool.submit(callableP); Future<String> submit2 = pool.submit(callableP); Future<String> submit3 = pool.submit(callableP); Future<String> submit4 = pool.submit(callableP); System.out.println("submit1 = " + submit1.get()); System.out.println("submit2 = " + submit2.get()); System.out.println("submit3 = " + submit3.get()); System.out.println("submit4 = " + submit4.get());
进程和线程
并发和并行 并发:同一间隔内,多个线程被Cpu调度执行,cpu轮询快速切换到不同线程,让其看到是同时执行
并行:同一时刻,多个线程被CPU调度执行
解释一:并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。
解释二:并行是在不同实体上的多个事件,并发是在同一实体上的多个事件。
解释三:并发是在一台处理器上“同时”处理多个任务,并行是在多台处理器上同时处理多个任务。如 hadoop 分布式集群。 所以并发编程的目标是充分的利用处理器的每一个核,以达到最高的处理性能。
并行
并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。所以无论从微观还是从宏观来看,二者都是一起执行的。
并发
并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。
线程生命周期 wait释放锁
sleep不释放锁
锁 悲观锁:在执行之前加锁,线程安全,性能较差
乐观锁:再执行之前认为他是安全的,等到遇到线程安全之后再加锁,线程安全,性能也好
CAS算法(WeakCompareAndSet比较和修改值)(改之前和原先的值进行比较)
先把10拿出来进行+1,11和原先的10作比较,10没有被其他人改就更新这个值,如果等于11了,这次就作废
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 package test;import java.io.Serializable;import java.util.List;import java.util.Random;public class SendThread extends Thread implements Serializable { private List<String> gift; private int count; public int getCount () { return count; } public void setCount (int count) { this .count = count; } public SendThread (List<String> gift, String name) { super (name); this .gift=gift; } public List<String> getGift () { return gift; } public void setGift (List<String> gift) { this .gift = gift; } @Override public void run () { Random random = new Random (); String name = Thread.currentThread().getName(); while (true ) { synchronized (gift){ if (gift.size()<10 ){ return ; } String s = gift.remove(random.nextInt(gift.size())); System.out.println(name+"发出" +s); this .count++; } } } } package test;import java.util.ArrayList;import java.util.List;import java.util.Random;public class Test01 { public static void main (String[] args) throws InterruptedException { List<String> gift = new ArrayList <>(); String[] names = {"口红" ,"包包" ,"鲜花" ,"皮带" ,"手表" }; Random random = new Random (); for (int i = 0 ; i < 100 ; i++) { gift.add(names[random.nextInt(names.length)] +(i+1 )); } SendThread xm = new SendThread (gift, "小明" ); xm.start(); SendThread xh = new SendThread (gift, "小红" ); xh.start(); xm.join(); xh.join(); System.out.println("xm.getCount() = " + xm.getCount()); System.out.println("xh.getCount() = " + xh.getCount()); } }
MySQL数据库 SQL语句 1、数据定义语言(DDL Data Definition Language) :创建、修改或删除数据库中表、视图、索引等对象的操作,常用命令为CREATE、DROP;
CREATE语句
2、数据操纵语言(DML Data Manipulation Language) :向表中添加、删除、修改数据操作,常用命令有insert、update和delete;
INSERT语句
3、数据查询语言(DQL Data Query Language) :按照指定的组合、条件表达式或排序检索已存在的数据库中数据,不改变数据库中数据,常用命令为select;
SELECT语句
4、数据控制语言(DCL Data Control Language) :用来授予或收回访问数据库的某种特权、控制数据操纵事务的发生时间及效果、对数据库进行监视等操作,常用命令有GRANT、REVOKE、COMMIT、ROLLBACK;
事务 简介 事务是一组操作的集合这组操作,要么全部成功,要么全部失败
事务操作 start transaction; –开启事务
commit/rollback; –提交回滚事务
事务的四大特性 原子性:事务是原子级别,要么全部执行成功,要么全部执行失败
一致性:事务完成时,必须所有的数据都要保持一致状态
隔离性:数据库提供的隔离机制,保证事务在不受外部并发操作影响下的独立环境下运行
持久性:事务一旦提交或者回滚,他对数据库的数据的改变是永久的
并发事务的问题 脏读:一个事务读取到另一个还未提交的数据(指更新或者删除未提交)
不可重复读:一个事务先后读取同一条数据,在第二次读之前被其他值修改(但是它未提交),但两次读取的数据不同
幻读:
开启一个事务,一个事务查询数据没查到,插入一条数据,在查询还是没查到,提交一下插入数据,然后查询一下又没查询到,但是在插入就显示已存在
事务的隔离级别
设置语句
set session transaction isolation level read uncommit;
存储引擎
不同存储引擎,索引结构是不同的
存储引擎简介 默认的是InnoDB存储引擎
存储引擎是存储数据、建立索引、更新查询数据等技术的实现方式。存储引擎是基于表而不是基于库,又被叫做表类型
创建表指定存储引擎 engine=InnoDB
展示所支持的存储引擎:shwo engines;
InnoDB 高可靠性,高性能
特点:事务、行级锁、外键
sdi:字典,ibd:每个表对应表空间
MyISAM 有表结构sdi 表数据myd 表索引myi
没有外键,删除和修改更好
Memory
三者关系 InnoDB和MyISAM
前者支持外键支持事务支持行级锁
后者不支持外键不支持事务支持表级锁
MyISAM 和 InnoDB区别 MyISAM 采用表级锁(table-level locking)。InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
表级锁和行级锁对比 表级锁: MySQL 中锁 粒度最大 ,对当前操作的整张表加锁,加锁的开销小,加锁快,不会出现死锁,(因为要么一次性获取全部的锁,要么等待)。其锁定粒度最大,触发锁冲突的概率高,并发度低。
引擎选择
InnoDB:事务完整比较高,数据一致性比较高,除了插入和查询之外,还包含了更新和删除
MyISAM :读和插入操作比较多时(MongDB)
Memory:访问速度比较快,适用于临时缓存,但表的大的话,就无法缓存到内存中(Redis)
docker配置mysql Linux——docker安装mysql8.0.31_牧魂.的博客-CSDN博客
–restart=always:总是跟随[docker启动]
索引 索引概述 索引是高效的数据结构,通过数据结构指向数据,快速查询数据,有序
优点:提高数据检索的效率,降低数据库的IO成本,查新快。
通过索引对数据进行排序,有效降低排序成本,降低cpu的消耗
缺点:索引占据空间,提高查询效率,而增删改的时候效率也会降低
索引结构
B树 二叉树(左小右大)
红黑树:相对平衡的二叉搜索树,但不是严格意义上的二叉搜索树,叶子和非叶子节点都会存储数据
B-tree树
5阶的,如果有四个了之后会发生裂变,让中间的数分裂上去
插入1200,大于4个节点,0345往上分列,形成
B+树
最多存储3个key和4个指针
数据都在叶子节点,每个叶子节点都会有一个双向链表,非叶子节点只存储索引的作用
Hash 哈希索引就是采用hash算法,将键值转换成新的hash值,映射到对应的槽位上,然后存储到hash表中。如果存在哈希碰撞,就需要连成链表去找对应的数据
思考题 为什么InnoDB存储引擎选择使用B+tree索引结构?
相对于二叉树,层级更少,搜索效率更高
对于B-tree,无论是叶子节点还是非叶子节点,都会存储数据,这样导致一页中存储的键值减少,指针跟着减少,要保存大量数据,只能增加树的高度,导致性能降低。而B+tree只有叶子节点存储数据,而非叶子节点就可以保存更多的键值,指针就会跟着增多
索引分类
主键索引:如果有主键,会自动创建主键索引
唯一索引:字段值不重复,比如身份证号
聚集索引挂的是一行的数据(是主键索引),而二级索引是挂的是主键
联合索引:多个列同时查询,最左匹配原则,搜索频繁最多的放在前面
回表查询是指先到二级索引拿到id,根据id去聚集索引查找行的数据
思考题
第一个查询快,因为第一个(id是主键)直接去聚集索引中根据id查;第二个是根据name所建立的索引,先去二级索引中根据name找所对应的id,再根据查到的id去聚集索引中查找所对应的行数据也称回表查询
高度为3,每个节点都有1171个指针,而每个节点都可以有1171个
索引语法
SQL性能分析 查看执行频次 select global status like ‘Com_______’;
后面7个_ 来查看哪个进行优化
慢查询日志 查看谁超过了默认的sql查询时间
只会记录执行时间超过预期时间的sql语句
show variables like ‘slow_query_log’;
profile select @@have_profiling;查询是否支持
查询每一个sql的执行耗时
explain 查询性能分析
id值越大先执行
在sql语句前面弄一个explain 然后就可以查看运行顺序
type 尽量往前提type,可以显示出性能好不好
索引的使用 没索引就是全表扫描
用索引就是构造b+树
最左前缀原则 联合索引,索引最左边的列必须存在,不能跳。如果最左边的列不存在,索引会失效走全表扫描
索引(a,b,c) 如果查询条件只有b和c,索引就失效,因为不符合最左前缀原则,a必须存在
如果查询 a和c 那么c会失效,因为没有b
索引失效和位置无关和存在有关
范围查询
联合查询(复合查询)
建议使用>=查询
如果是>后面的索引都会失效
要是>=后面的索引不会失效
联合查询可以解决回表查询
索引失效情况 不要在索引列上进行运算操作
比如
索引会失效
字符串不加引号,会造成类型转换
字符串类型使用时,不加引号,索引会失效
模糊匹配
%在前面就会失效,%在后面就不会失效,要规避前面是%的模糊查询
or
or左右条件都有索引的话,才会索引生效
or左右有一个就不生效
age没索引
age有索引
数据分布影响
mysql会评估到使用索引比全表更慢,则不使用索引,索引会失效
SQL使用提示 要是有一个列即在联合索引又在常规索引里,它默认使用的是联合索引
use index(索引名) 可以在from 表名后使用 use index(索引名)来指定,可能会评估,不使用
ignore index(忽略的索引名)
force index (强制的索引名)
覆盖索引
覆盖索引是在二级索引中,都显示的属性,就不需要回表查询
前缀索引 截取字符串长的
不重复/总数=选择性
单列索引/联合索引 优先推荐联合索引,性能高,使用得当就会避免回调查询
索引设计原则
SQL优化 insert优化 批量插入、手动提交事务、主键顺序插入
大批量数据使用load指令local data local infile
主键顺序插入性能高于乱序插入
主键优化 页分裂和页合并
主键乱序插入会造成页分裂
页分裂:乱序插入,50插入,会开启新的数据页,将第一页中后超出50%的部分插入到第三个数据页,将50插入到第三页,然后第一页双向链表和第三个双向链表连接
主键过长,查得慢,而且占空间
order by优化 排序字段尽量使用索引,使用覆盖索引
using index 直接通过索引返回数据,性能高
using filesort 需要将返回的结果在缓冲区中排序
排序时,先根据想要排序的顺序建立索引,比如想age升序,name降序 然后可以建立索引 create index yb_k on emp(age asc ,name desc)建立索引,就不会出现filesort了,这样不会慢。默认都是升序
order by最左前缀法则 顺序好像必须一致
where 存在就行
查询时出现using temportary就会产生临时表,会使查询变慢
group by分组优化 推荐建立索引使用联合索引
group by最左前缀法则 顺序好像必须一致
用到临时表就是很慢,就需要建立索引
Limit优化 通过覆盖索引和子查询的优化
count优化 推荐使用count(*) 专门进行了优化 直接进行累加,不需拿值,不需判断为null
update优化 where要有索引的字段,并且索引不能失效
可以先查出有索引的字段,然后根据查出来的索引字段进行更新
update s set gender=’男’ where id (select id from emp where gender=’女’);
这样就很快,走的是聚集索引,不会进行回表查询
如果根据索引条件更新某一字段值,走的是行锁
如果根据某一字段值更新某一字段值,走的是表锁,因为没有加索引会全表扫描这个条件字段值
行锁升级为表锁,会降低并发访问性能
总结
表锁
特点:偏向MyISAM存储引擎,开销小,加锁快;无死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行锁
特点:偏向InnoDB存储引擎,和表锁相反
mysql中表锁和行锁有什么区别-mysql教程-PHP中文网
视图 视图介绍 视图是一个虚表,并不真实存在,里面的数据是动态生成的
视图相当于一个封装好的select函数
视图语法 创建视图
create (or repalce) view emp_v1 as select id, name from emp;
查看视图
SHOW CREATE VIEW 视图名称
修改视图
create or repalce view emp_v1 as select id, name from emp;
alter view emp_v1 as select * from emp;
删除视图
drop view if exists emp_v1;
检查选项cascaded
哪一句加这个选项,这一句和所依赖的上一句都会检查所插入的是否满足where条件
没有这个选项,就不会检查是否满足索引的条件,都会插到表里面
检查会向上传递
检查选项local 哪一句加这个选项,这一句会检查是否满足条件,所依赖的上一句如果有with local check option会判断是否满足条件,没有就不判断
local 不会向上传递
视图的更新 视图中的行和表中的行必须是一一对应的关系
不能包含以下:
案例
(1)
创建视图,缺少那两列
(2)将学生选修课程表很常用,可以将其弄成视图,真实表不存在,可以后面操作视图 封装了查询语句,简化了操作
存储过程 介绍 封装sql语句
基本语法
创建存储过程
1 2 3 4 create procedure p1() begin select count(*) from emp end;
调用存储过程
call p1();
查看存储过程
删除存储过程
drop procedure if exists p1()
设置结束符 delimiter $$
在结束写上$$表示结束
变量-系统变量
show global variables; //所有系统变量
show variables like ‘slow_query_log’; //模糊查询系统变量
select @@global 系统变量名 —查看指定的变量值
不指定的话,默认是会话记录
用户定义变量
set @myname = ‘kang’;
select @myname
直接跳过存储过程到触发器 触发器 介绍
保持数据完整性和日志记录和数据校验
在数据的增删改之前或者之后进行日志操作
语法
案例 插入数据的触发器
字符串拼接 concat
更改数据的触发器
<5触发4次触发器,因为是行级触发器
删除数据的触发器
总结
锁 全局锁 当前使用哪个数据库,就锁哪个数据库
在对整个库进行逻辑备份时,如果不加全局锁,由于数据库的备份不可能一瞬间完成,那么将可能造成最终数据不一致的问题。
数据备份,加全局锁,不让其他用户对这个表进行DDL,和DML操作,只能进行DQL,保护数据的完整性。只能读

一致性数据备份 全局锁锁的一般都是当前使用的数据库
快照读来备份,不需要加锁 single-transation
表级锁 锁定粒度大,每次操作锁住整张表,发生锁冲突的概率最高,并发度最低
表锁 分为:读锁和写锁
读锁:限制DML语句,仅能读表数据 共享锁 本机客户端只能读不能写,其他客户端只能读不能写
写锁:限制其他客户端对表的DML和DQL操作,本机客户端既能进行DML还能进行DQL 排它锁/独占锁
元数据锁 元数据锁是为了在操作表结构的时候,比如修改表的结构,加上元数据锁,为了避免DML语句对表中的数据做出改变。 默认会加元数据锁
也是在DML操作表数据的时候不能改变表的结构
意向锁 避免行锁和表锁加锁的冲突问题
表锁,有行锁然后自动给表加意向锁
InnoDb引擎中,表锁和行锁的冲突问题
意向共享锁:两个事务,事务1读数据,事务2可以加表锁读锁
意向排他锁:事务1写数据,事务2读写都不可以,不兼容。但是和意向锁兼容
再执行select的时候,会自动加上表的意向共享锁,也会加行锁
update 这一行会加行锁。并加上表意向排他锁,然后既不能DML也不能DQL
行级锁 对操作的行加锁,通过对索引上的索引项来加锁,而不是对记录来加锁
行锁 在读一行的时候允许别人读,但是不允许别人改
在修改一行数据的时候,不允许别人读和改
next-key是临建锁
间隙锁 临建锁 间隙锁为了防止幻读 防止其他事务插入数据(但是它不能插入),然后造成事务插入异常
针对第二条:1,3,5,7 在5之前是临建锁,那么在5-7是间隙锁
InnoDB引擎 逻辑存储结构 表空间:一个mysql实例可以对应多个表空间,用于存储记录、索引等数据
架构一 缓冲池
更改缓冲区
自适应Hash索引
日志缓冲区
创建表空间
架构
架构:
增删改查操作缓冲区,如果缓冲区没有数据就在磁盘中读取放到缓冲区里面。缓冲区里面的数据将通过后台线程异步刷新到磁盘中,保持数据的一致
InnoDB事务管理
redo log
操作缓冲区,然后把修改的数据放到redo.log ,然后这个log会往磁盘中输出一个文件,然后这个文件是为了防止刷新脏页到磁盘出现问题,导致没同步。这个文件就可以将信息同步到磁盘中
undo log
MVCC 在快照读的时候通过mvcc找到对应的历史版本
概念
隐藏字段
undo log
readview
readview 里面有4个属性,来判断应该读取哪个版本
MYSQL管理 系统数据库
常用工具 mysql
mysqladmin 创建删除数据库
mysqlbinlog 二进制日志管理工具
mysqlshow 查看表中列和索引 mysqlshow -uroot -p1234 db01 –count
mysqlshow -uroot -p1234 db01 -i
mysqldump数据备份
mysqlimport/source 导入mysqldump 加-T参数后导出的文本文件 source可以导入sql脚本
进阶篇总结
日志 错误日志 记录了mysql启动和停止的日志
tail -f 尾部查看日志
二进制日志
show variables like’%log_bin%’;
-v v 将事件重构为sql语句,并输出注释信息
show variables like ‘%binlog_expire_logs_seconds%’;
30天
查询日志
慢查询日志 查看哪个sql语句超过了执行时间
主从复制 概述
原理 
主库有事务提交时,把数据的变更写入二进制文件;
从库IOthread读取主库二进制文件并写入到从库Replay_log(中继)日志中;
从库又会SQLThread重做日志中的事件,改变反映自己的数据;
主库配置 主库ip 192.168.237.124
从库ip 192.168.237.128
搭建 1.修改配置文件 /etc/my.cnf
2.重启mysql服务器
3.登录,mysql创建远程连接的账号,并授予主从复制的权限
可以让从库用这个账户和密码连接主库
create user ‘kang‘@’%’ identified with mysql_native_password by ‘Root@123456’;
账户名 itcast %这一用户可以在任意主机都可以访问这台服务器 密码Root@123456
grant replication slave on . to ‘kang‘@’%’;
4.通过指令查看二进制日志文件的坐标
flush privileges;
从库配置 搭建 1.修改配置文件 /etc/my.cnf
2.重启mysql服务器
3.登录mysql,设置主从复制
change master to master_host =’192.168.237.124’,master_user=’kang’,master_password=‘Root@123456’,master_log_file=’ binlog.000028’,master_log_pos=156;
4.开启同步操作
start replica;
5.查看从库状态
show slave status\G;
uuid 所在目录 /var/lib/docker/volumes/9294e8036fb5c1fd3eb8a1f691be8f1d62ea8475821976a1e016a7a251701533/_data/auto.cnf
Mysql主从同步报错解决:Fatal error: The slave I/O thread stops because master and slave have equal..-CSDN博客
CHANGE MASTER TO
解决:server相同,日志不是第一个问题
Mysql报错:Got fatal error 1236 from master when reading data from binary log: ‘Could not find first lo_上海运维Q先生的博客-CSDN博客
set global server_id=128;
select @@server_id;
读写分离 主库写从库读
ShardingJDBC 1.导入依赖
1 2 3 4 5 6 <!--sharding-jdbc依赖--> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.0.0-RC1</version> </dependency>
2.在yml配置读写分离规则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 spring: shardingsphere: datasource: names: master,slave master: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.237.124:3306/rw?characterEncoding=utf-8 username: root password: 123456 slave: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.237.128:3306/rw?characterEncoding=utf-8 username: root password: 123456 masterslave: load-balance-algorithm-type: round_robin name: dataSource master-data-source-name: master slave-data-source-names: slave props: sql: show: true main: allow-bean-definition-overriding: true
3.在配置文件中配置允许bean定义覆盖配置项
SpringBootConfiguration 和 DruidDataSourceAutoConfigure 都会创建一个数据源,导致报错。所以必须允许bean定义覆盖,用最新的
JWT
生成
解析
Nginx
maven 继承 我们可以再创建一个父工程 tlias-parent ,然后让上述的三个模块 tlias-pojo、tlias-utils、tlias-web-management 都来继承这个父工程 。 然后再将各个模块中都共有的依赖,都提取到父工程 tlias-parent中进行配置,只要子工程继承了父工程,依赖它也会继承下来,这样就无需在各个子工程中进行配置了。
概念:继承描述的是两个工程间的关系,与java中的继承相似,子工程可以继承父工程中的配置信息,常见于依赖关系的继承。
作用:简化依赖配置、统一管理依赖
聚合
聚合: 将多个模块组织成一个整体,同时进行项目的构建。聚合工程: 一个不具有业务功能的“空”工程(有且仅有一个pom文件) 【PS:一般来说,继承关系中的父工程与聚合关系中的聚合工程是同一个】作用: 快速构建项目(无需根据依赖关系手动构建,直接在聚合工程上构建即可)
可以统一打包
版本锁定 在maven中,可以在父工程的pom文件中通过 来统一管理依赖版本。
父工程:
1 2 3 4 5 6 7 8 9 10 11 <!--统一管理依赖版本--> <dependencyManagement> <dependencies> <!--JWT令牌--> <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt</artifactId> <version>0.9 .1 </version> </dependency> </dependencies> </dependencyManagement>
子工程:
1 2 3 4 5 6 7 <dependencies> <!--JWT令牌--> <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt</artifactId> </dependency> </dependencies>
注意:
在父工程中所配置的 只能统一管理依赖版本,并不会将这个依赖直接引入进来。 这点和 是不同的。 版本号了,父工程统一管理。变更依赖版本,只需在父工程中统一变更。
分模块开发 分模块设计之后,如果我们需要用到另外一个模块的功能,我们直接依赖模块就可以了。比如商品模块、搜索模块、购物车订单模块都需要依赖于通用组件当中封装的一些工具类,我只需要引入通用组件的坐标就可以了。
分模块设计就是将项目按照功能/结构拆分成若干个子模块,方便项目的管理维护、拓展,也方便模块键的相互调用、资源共享。
三更Blog 项目介绍 项目介绍: 博客项目,前端有两个系统,分别是负责博客页面(前台系统)、管理页面(后台系统)。后端也有两个系统,分别是前端两个系统的具体实现
思考: 后端两个系统的代码复用性较高,所以后端创建的是多模块(3个模块)项目,把后端两个系统(两个子模块)都会用到的代码写到一个公共模块(第3个模块)
3个子模块在父模块里面,父模块叫SpringBootBlog
3个子模块分别是dykang-framework(公共模块)、dykang-blog(博客前台模块)、dykang-admin(博客后台模块)
项目搭建 创建父模块dy-Blog
把src目录删掉
在pom.xml添加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion>4.0 .0 </modelVersion> <groupId>com.kang</groupId> <artifactId>dy-Blog</artifactId> <packaging>pom</packaging> <version>1.0 -SNAPSHOT</version> <!-- 聚合工程,可以一起打包,一起清理,更加方便--> <modules> <module >dykang-framework</module > <module >dykang-blog</module > <module >dykang-admin</module > </modules> <!-- 多模块开发,提高系统的复用性--> <!--编码方式、jdk版本--> <properties> <project.build.sourceEncoding>UTF-8 </project.build.sourceEncoding> <java.version>1.8 </java.version> </properties> <!--依赖的版本控制--> <dependencyManagement> <dependencies> <!-- SpringBoot的依赖配置--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.5 .0 </version> <type>pom</type> <scope>import </scope> </dependency> <!--fastjson依赖--> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2 .33 </version> </dependency> <!--jwt依赖--> <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt</artifactId> <version>0.9 .0 </version> </dependency> <!--mybatisPlus依赖--> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4 .3 </version> </dependency> <!--阿里云OSS--> <dependency> <groupId>com.aliyun.oss</groupId> <artifactId>aliyun-sdk-oss</artifactId> <version>3.10 .2 </version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> <version>3.0 .5 </version> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> <version>2.9 .2 </version> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger-ui</artifactId> <version>2.9 .2 </version> </dependency> </dependencies> </dependencyManagement> <build> <plugins> <plugin> <!--配置maven版本--> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1 </version> <!--配置jdk版本--> <configuration> <source>${java.version}</source> <target>${java.version}</target> <encoding>${project.build.sourceEncoding}</encoding> </configuration> </plugin> </plugins> </build> </project>
创建公共子模块dykang-framework 在pox.xml添加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <parent> <artifactId>dy-Blog</artifactId> <groupId>com.kang</groupId> <version>1.0 -SNAPSHOT</version> </parent> <modelVersion>4.0 .0 </modelVersion> <!-- 公共模块--> <artifactId>dykang-framework</artifactId> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--lombok--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true </optional> </dependency> <!--junit--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--SpringSecurity启动器--> <!--<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> </dependency>--> <!--redis依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <!--fastjson依赖--> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> </dependency> <!--jwt依赖--> <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt</artifactId> </dependency> <!--mybatisPlus依赖--> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> </dependency> <!--mysql数据库驱动--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <!--阿里云OSS--> <dependency> <groupId>com.aliyun.oss</groupId> <artifactId>aliyun-sdk-oss</artifactId> </dependency> <!--AOP--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger-ui</artifactId> </dependency> </dependencies> </project>
创建博客后台模块dykang-admin 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <parent> <artifactId>dy-Blog</artifactId> <groupId>com.kang</groupId> <version>1.0 -SNAPSHOT</version> </parent> <modelVersion>4.0 .0 </modelVersion> <!-- 管理后台页面--> <artifactId>dykang-admin</artifactId> <!--用dykang-framework模块里面的依赖--> <dependencies> <dependency> <groupId>com.kang</groupId> <artifactId>dykang-framework</artifactId> <version>1.0 -SNAPSHOT</version> </dependency> </dependencies> </project>
创建博客前台模块dykang-blog 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <parent> <artifactId>dy-Blog</artifactId> <groupId>com.kang</groupId> <version>1.0 -SNAPSHOT</version> </parent> <modelVersion>4.0 .0 </modelVersion> <!-- 管理前台页面--> <artifactId>dy-blog</artifactId> <!--用dykang-framework模块里面的依赖--> <dependencies> <dependency> <groupId>com.kang</groupId> <artifactId>dykang-framework</artifactId> <version>1.0 -SNAPSHOT</version> </dependency> </dependencies> </project>
EasyCode插件 快速生成实体类等代码
公共模块-准备工作 导入数据库
测试
博客前台模块-准备工作 整合mybatisplus
博客前台模块-文章列表 接口分析 需要查询浏览量最高的前10篇文章的信息。要求展示文章标题和浏览量。把能让用户自己点击跳转到具体的文章详情进行浏览
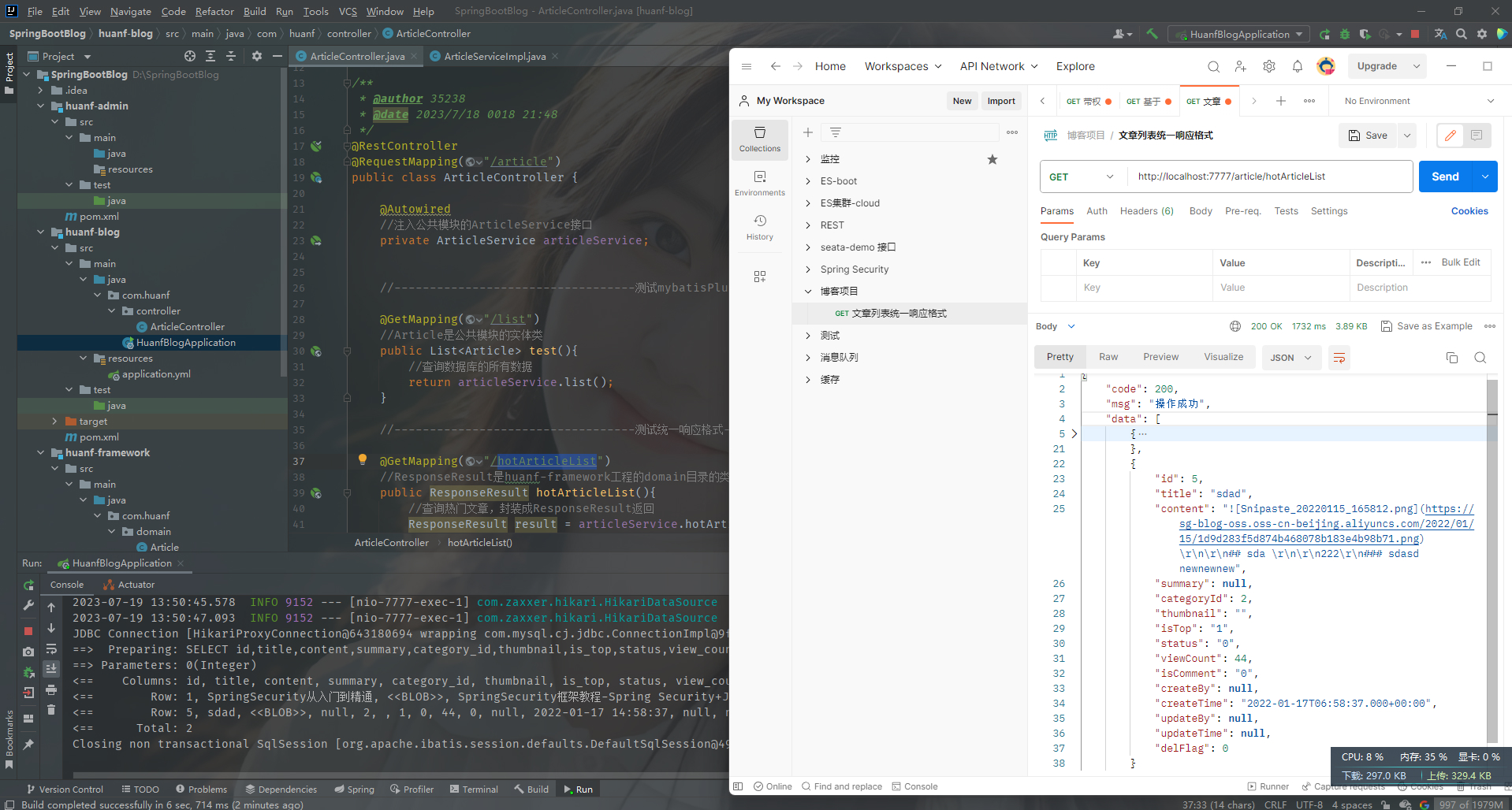
注意:不能把草稿展示出来,不能把删除了的文章查询出来。要按照浏览量进行降序排序
解决思路 构造查询条件:已发布文章,未删除文章(yml逻辑删除字段已自动判断是否删除,在这就不用加入此条件) ,通过降序排序 并只查看10条数据 所以用分页查询,直接表明是第一页显示10个数据即可 通过查询条件查询出文章表信息 通过BeanCopy给VO,并返回给前端
统一响应格式 1.代码实现 第一步: 在huanf-framework公共模块的src/main/java目录新建com.huanf.enums.AppHttpCodeEnum类,写入如下,作用是封装code和msg
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package com.huanf.enums;public enum AppHttpCodeEnum { SUCCESS(200 ,"操作成功" ), NEED_LOGIN(401 ,"需要登录后操作" ), NO_OPERATOR_AUTH(403 ,"无权限操作" ), SYSTEM_ERROR(500 ,"出现错误" ), USERNAME_EXIST(501 ,"用户名已存在" ), PHONENUMBER_EXIST(502 ,"手机号已存在" ), EMAIL_EXIST(503 , "邮箱已存在" ), REQUIRE_USERNAME(504 , "必需填写用户名" ), LOGIN_ERROR(505 ,"用户名或密码错误" ); int code; String msg; AppHttpCodeEnum(int code, String errorMessage){ this .code = code; this .msg = errorMessage; } public int getCode () { return code; } public String getMsg () { return msg; } }
第二步: 在huanf-framework公共模块的domain目录新建ResponseResult类,写入如下,作为统一响应格式的类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 package com.huanf.domain; public ResponseResult<?> ok(Integer code, T data) { this .code = code; this .data = data; return this ; } public ResponseResult<?> ok(Integer code, T data, String msg) { this .code = code; this .data = data; this .msg = msg; return this ; } public ResponseResult<?> ok(T data) { this .data = data; return this ; } public Integer getCode () { return code; } public void setCode (Integer code) { this .code = code; } public String getMsg () { return msg; } public void setMsg (String msg) { this .msg = msg; } public T getData () { return data; } public void setData (T data) { this .data = data; } }
2.后端解决跨域 在huanf-framework工程的src/main/java目录新建com.huanf.config.WebConfig类,写入如下,然后重新运行huanf-blog工程的HuanfBlogApplication类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package com.huanf.config;import org.springframework.context.annotation.Configuration;import org.springframework.web.servlet.config.annotation.CorsRegistry;import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;@Configuration public class WebConfig implements WebMvcConfigurer { @Override public void addCorsMappings (CorsRegistry registry) { registry.addMapping("/**" ) .allowedOriginPatterns("*" ) .allowCredentials(true ) .allowedMethods("GET" , "POST" , "DELETE" , "PUT" ) .allowedHeaders("*" ) .maxAge(3600 ); } }
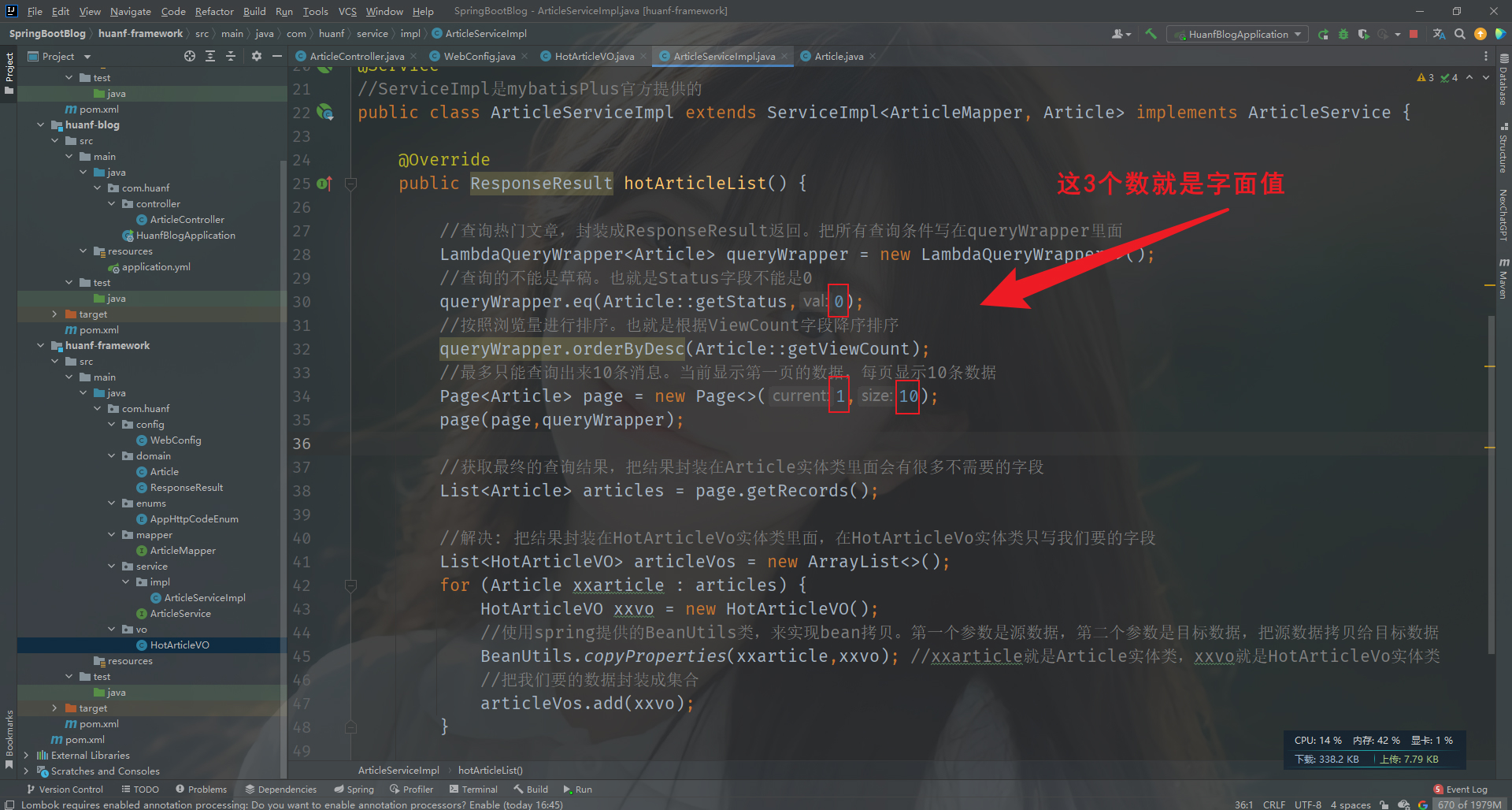
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Service public class ArticleServiceImpl extends ServiceImpl <ArticleMapper, Article> implements ArticleService { @Override public ResponseResult hotArticleList () { LambdaQueryWrapper<Article> queryWrapper = new LambdaQueryWrapper <>(); queryWrapper.eq(Article::getStatus,0 ); queryWrapper.orderByDesc(Article::getViewCount); Page<Article> page = new Page <>(1 ,10 ); page(page,queryWrapper); List<Article> articles = page.getRecords(); return ResponseResult.okResult(articles); }
3、前端项目的启动 需要有node.js
1 2 3 cd /SpringBootBlogWeb/sg-blog-vue npm install npm run dev
4.统一响应格式(优化) vo 在刚刚的响应格式中,其实是不符合接口文档标准的,因为我们返回了很多字段,如下图,有些字段不需要返回,或者比较敏感不能返回给前端
为什么会返回这么多字段: 查询出来的结果是用Article来封装的,由于Article实体类里面的字段比较多,所以返回的字段也就是很多
解决: 用VO (是Value Object的缩写,表示值对象) 来接收查询的结果,一个接口对应一个VO,这样即使接口响应字段要修改也只要修改VO即可
Bean拷贝:
1 BeanUtils.copyProperties(xxarticle,xxvo);
字面值处理 实际项目中都不允许直接在代码中使用字面值(代码中的固定值)。都需要定义成常量来使用。这种方式有利于提高代码的可维护性。字面值如下图
第一步: 在huanf-framework工程的src/main/java目录新建com.huanf.constants.SystemCanstants类,写入如下,作用是定义常量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package com.huanf.constants;public class SystemCanstants { public static final int ARTICLE_STATUS_DRAFT = 1 ; public static final int ARTICLE_STATUS_NORMAL = 0 ; public static final int ARTICLE_STATUS_CURRENT = 1 ; public static final int ARTICLE_STATUS_SIZE = 10 ; }
Bean拷贝的封装 在前面的 ‘统一响应格式(优化)’ 的 ‘一、定义并测试VO’,最核心的代码就是ArticleServiceImpl类里面用到的Spring提供的BeanUtils工具类。这个工具类可以把Article类里面拿到的查询结果,拷贝给HotArticleVO类,注意HotArticleVO(少)相对于Article(多)来说,成员变量的数量可以少,但是名称和类型必须一样
我们前面是在ArticleServiceImpl类写了如下核心代码,为了提高代码复用性,我们必须把这段代码抽取出来进行封装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package com.huanf.utils;import org.springframework.beans.BeanUtils;import java.util.List;import java.util.stream.Collectors;public class BeanCopyUtils { private BeanCopyUtils () { } public static <V> V copyBean (Object source,Class<V> clazz) { V result = null ; try { result = clazz.newInstance(); BeanUtils.copyProperties(source, result); } catch (Exception e) { e.printStackTrace(); } return result; } public static <O,V> List<V> copyBeanList (List<O> list,Class<V> clazz) { return list.stream() .map(o -> copyBean(o, clazz)) .collect(Collectors.toList()); } }
修改之前copy代码
1 2 3 List<HotArticleVO> articleVos = BeanCopyUtils.copyBeanList(articles, HotArticleVO.class);
博客前台模块-分类列表 接口分析 页面上需要展示分类列表,用户可以点击具体的分类查看该分类下的文章列表。要求只展示有发布正式文章的分类 。要求必须是正常(非禁用)状态的分类
解决思路 首先查询文章表中状态正常的文章分类ID集合并去重,通过调用listByIds获取分类相关信息,然后通过stream流过滤出状态正常的分类信息,通过BeanCopy把信息拷贝到VO对象,将VO对象返回给前端
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 @Service("categoryService") public class CategoryServiceImpl extends ServiceImpl <CategoryMapper,Category> implements CategoryService { @Autowired private ArticleService articleService; @Override public ResponseResult getCategoryList () { LambdaQueryWrapper<Article> articleWrapper = new LambdaQueryWrapper <>(); articleWrapper.eq(Article::getStatus, SystemCanstants.ARTICLE_STATUS_NORMAL); List<Article> articleList = articleService.list(articleWrapper); Set<Long> categoryIds = articleList.stream() .map(new Function <Article, Long>() { @Override public Long apply (Article article) { return article.getCategoryId(); } }) .collect(Collectors.toSet()); List<Category> categories = listByIds(categoryIds); categories = categories.stream() .filter(category -> SystemCanstants.STATUS_NORMAL.equals(category.getStatus())) .collect(Collectors.toList()); List<CategoryVo> categoryVos = BeanCopyUtils.copyBeanList(categories, CategoryVo.class); return ResponseResult.okResult(categoryVos); } }
博客前台模块-分页查询 接口分析 首页需要查询所有的文章列表。分类页面需要查询对应分类下的文章列表。只能查询正式发布的文章,置顶的文章要显示在最前面
解决思路 首先看到分页,先配置MP分页插件;
查询条件为 正常发布的文章,置顶的文章(降序排序即可),分类名,文章实体类中没有需要添加,并加入注解TableField(exists=false)在数据库表中实际不存在 ;通过分类ID查找分类表获取分类名,封装分页VO对象返回
配置分页插件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Configuration public class MybatisPlusConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor () { MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor (); mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor ()); return mybatisPlusInterceptor; } }
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Override public ResponseResult articleList (Integer pageNum, Integer pageSize, Long categoryId) { LambdaQueryWrapper<Article> lambdaQueryWrapper = new LambdaQueryWrapper <>(); lambdaQueryWrapper.eq(Objects.nonNull(categoryId)&&categoryId>0 ,Article::getCategoryId,categoryId); lambdaQueryWrapper.eq(Article::getStatus,SystemCanstants.ARTICLE_STATUS_NORMAL); lambdaQueryWrapper.orderByDesc(Article::getIsTop); Page<Article> page = new Page <>(pageNum,pageSize); page(page,lambdaQueryWrapper); List<ArticleListVo> articleListVos = BeanCopyUtils.copyBeanList(page.getRecords(), ArticleListVo.class); PageVo pageVo = new PageVo (articleListVos,page.getTotal()); return ResponseResult.okResult(pageVo); }
解决categoryName没有名字问题 for循环解决
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 List<Article> articles = page.getRecords(); for (Article article : articles) { Category category = categoryService.getById(article.getCategoryId()); article.setCategoryName(category.getName()); } List<Article> articles = page.getRecords(); articles.stream() .map(new Function <Article, Article>() { @Override public Article apply (Article article) { Category category = categoryService.getById(article.getCategoryId()); String name = category.getName(); article.setCategoryName(name); return article; } }) .collect(Collectors.toList());
1 2 3 4 @TableField(exist = false) private String categoryName;
FastJson配置 由于ArticleListVO类的createTime成员变量是Date类型,默认是由java的Jackson来处理,使用 ISO-8601 规范来处理日期时间格式。ISO-8601 是一种国际标准的日期时间表示法,例如:”2023-07-21T06:53:24”。我们不希望时间被处理成这种格式,如下图。解决: 使用FastJson
也可以通过注解的方式,在日期字段上面加入@JsonFormat(pattern = “yyyy-MM-dd HH:mm:ss”)也可
第一步(已做可跳过): 在huanf-framework的pom.xml添加如下
1 2 3 4 5 <!--fastjson依赖--> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> </dependency>
第二步: 在huanf-framework的config目录的WebConfig类,修改为如下。用线隔开了。直接复制去用
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 package com.huanf.config; import com.alibaba.fastjson.serializer.SerializeConfig; import com.alibaba.fastjson.serializer.SerializerFeature; import com.alibaba.fastjson.serializer.ToStringSerializer; import com.alibaba.fastjson.support.config.FastJsonConfig; import com.alibaba.fastjson.support.spring.FastJsonHttpMessageConverter; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.http.converter.HttpMessageConverter; import org.springframework.web.servlet.config.annotation.CorsRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; import java.util.List; /** \* @author 35238 \* @date 2023/7/19 0019 14:57 */ @Configuration public class WebConfig implements WebMvcConfigurer { @Override public void addCorsMappings(CorsRegistry registry) { // 设置允许跨域的路径 registry.addMapping("/**") // 设置允许跨域请求的域名 .allowedOriginPatterns("*") // 是否允许cookie .allowCredentials(true) // 设置允许的请求方式 .allowedMethods("GET", "POST", "DELETE", "PUT") // 设置允许的header属性 .allowedHeaders("*") // 跨域允许时间 .maxAge(3600); } //-----------------------------------FastJson配置----------------------------------------- @Bean//使用@Bean注入fastJsonHttpMessageConvert public HttpMessageConverter fastJsonHttpMessageConverters() { //1.需要定义一个Convert转换消息的对象 FastJsonHttpMessageConverter fastConverter = new FastJsonHttpMessageConverter(); FastJsonConfig fastJsonConfig = new FastJsonConfig(); fastJsonConfig.setSerializerFeatures(SerializerFeature.PrettyFormat); fastJsonConfig.setDateFormat("yyyy-MM-dd HH:mm:ss"); SerializeConfig.globalInstance.put(Long.class, ToStringSerializer.instance); fastJsonConfig.setSerializeConfig(SerializeConfig.globalInstance); fastConverter.setFastJsonConfig(fastJsonConfig); HttpMessageConverter<?> converter = fastConverter; return converter; } @Override //配置消息转换器 public void configureMessageConverters(List<HttpMessageConverter<?>> converters) { //增加我们的消息转换器 converters.add(fastJsonHttpMessageConverters()); } //-------------------------------------------------------------------------------------- }
博客前台模块-文章详情 接口分析 要求在文章列表点击阅读全文时能够跳转到文章详情页面,可以让用户阅读文章正文。并且要在文章详情中展示其分类名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "code" : 200 , "data" : { "categoryId" : "1" , "categoryName" : "java" , "content" : "文章详情的具体文章内容" , "createTime" : "2022-01-23 23:20:11" , "id" : "1" , "isComment" : "0" , "title" : "SpringSecurity从入门到精通" , "viewCount" : "114" } , "msg" : "操作成功" }
解决思路 路径参数需要加入@PathVariable标明是路径参数
根据传入id,找到这个文章,获取文章分类ID,然后根据文章分类ID获取分类名称,BeanCopy给VO对象
Http请求方式 以GET /article/{id} 为例的路径参数形式,下面两种是比较常用的。不常用的有’请求体形式’、’请求头形式’
请求形式
示例
描述
路径参数形式
/articles/{id}
参数作为路径的一部分,表示明确的资源标识符或必需的参数。
查询参数形式
/articles?id=1&num=1
参数通过 “?” 或 “&” 的方式附加在URL的末尾,适合传递可选参数或过滤条件。
在上面的业务请求中,我们使用的都是’路径参数形式’,下面的业务请求中,我们将会使用’查询参数形式’
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 @GetMapping("/{id}") public ResponseResult getArticleDetail (@PathVariable("id") Long id) { return articleService.getArticleDetail(id); } @Override public ResponseResult getArticleDetail (Long id) { Article article = getById(id); ArticleDetailVo articleDetailVo = BeanCopyUtils.copyBean(article, ArticleDetailVo.class); Long categoryId = articleDetailVo.getCategoryId(); Category category = categoryService.getById(categoryId); if (category!=null ){ articleDetailVo.setCategoryName(category.getName()); } return ResponseResult.okResult(articleDetailVo); }
博客前台模块-友链功能 接口分析 在友链页面要查询出所有的审核通过的友链,响应格式如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 { "code" : 200 , "data" : [ { "address" : "https://www.baidu.com" , "description" : "sda" , "id" : "1" , "logo" : "图片url1" , "name" : "sda" } , { "address" : "https://www.qq.com" , "description" : "dada" , "id" : "2" , "logo" : "图片url2" , "name" : "sda" } ] , "msg" : "操作成功" }
解决思路 条件:审核通过即可,查询出直接BeanCopy对象返回
代码实现 @Service(“linkService”)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override public ResponseResult getAllLink () { LambdaQueryWrapper<Link> queryWrapper = new LambdaQueryWrapper <>(); queryWrapper.eq(Link::getStatus, SystemCanstants.LINK_STATUS_NORMAL); List<Link> links = list(queryWrapper); List<LinkVo> linkVos = BeanCopyUtils.copyBeanList(links, LinkVo.class); return ResponseResult.okResult(linkVos); }
博客前台模块-登录功能 SpringSecrity
1 2 3 登录:通过过滤器,没有token放行,让他执行登录接口,去查询数据库,将数据库中的用户名、密码和权限信息放到loginuser中,登录管理器会通过BC密码验证规则去验证密码是否正确(管理器里面会首先把得到的密码BC处理,然后和UserDetails对比),正确将loginuser信息存到authiencation中返回,然后在里面获取token并返回给前端,loginuser信息放到redis中,以便于登录过得用户携带相关权限信息进行判断是否能执行相应操作,然后登录成功。 接口:携带相关权限和token被jwt认证过滤器拦截,判断token是否正确,正确解析token获得登录用户id,然后从redis中获得相关权限信息集合,将权限信息和loginuser 保存到securitycontextholder中,然后放行后续过滤器会从securitycontextholder中获取相关信息选择放行 权限认证:将controller层接口上携带权限校验的权限信息,和securitycontextholder中的权限信息进行比对,有就返回true就有权限。 因为访问接口前需要经过jwt认证处理器,所以securitycontextholder中会有相关的权限信息拿来比对




接口分析 请求体
1 2 3 4 { "userName":"sg", "password":"1234" }
响应格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "code" : 200 , "data" : { "token" : "eyJhbGciOiJIUzI1NiJ9.eyJqdGkiOiI0ODBmOThmYmJkNmI0NjM0OWUyZjY2NTM0NGNjZWY2NSIsInN1YiI6IjEiLCJpc3MiOiJzZyIsImlhdCI6MTY0Mzg3NDMxNiwiZXhwIjoxNjQzOTYwNzE2fQ.ldLBUvNIxQCGemkCoMgT_0YsjsWndTg5tqfJb77pabk" , "userInfo" : { "avatar" : "https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fi0.hdslb.com%2Fbfs%2Farticle%2F3bf9c263bc0f2ac5c3a7feb9e218d07475573ec8.gi" , "email" : "23412332@qq.com" , "id" : 1 , "nickName" : "sg333" , "sex" : "1" } } , "msg" : "操作成功" }
思路分析 登录
①自定义登录接口
调用ProviderManager的方法进行认证 如果认证通过生成jwt
把用户信息存入redis中
②自定义UserDetailsService
在这个实现类中去查询数据库,返回UserDetails实现类对象
注意配置passwordEncoder为BCryptPasswordEncoder
UserDetails实现类对象的密码和Authentication密码相比较,相同将UserDetails实现类对象的权限信息交给Authentication对象
校验:
①定义Jwt认证过滤器
获取token
解析token获取其中的userid
从redis中获取用户信息
存入SecurityContextHolder,以便后面过滤器拿来使用
配置
① 登录管理器ProviderManager
BCryptPasswordEncoder密码校验
JWT认证过滤器
权限和认证异常处理器
crsf攻击
cors跨域
代码实现 登录接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 @Service public class BlogLoginServiceImpl implements BlogLoginService { @Autowired private UserDao userDao; @Autowired private RedisCache redisCache; @Autowired private AuthenticationManager authenticationManager; @Override public ResponseResult login (User user) { UsernamePasswordAuthenticationToken usernamePasswordAuthenticationToken = new UsernamePasswordAuthenticationToken (user.getUserName(),user.getPassword()); Authentication authenticate = authenticationManager.authenticate(usernamePasswordAuthenticationToken); if (Objects.isNull(authenticate)){ throw new RuntimeException ("用户名或密码错误" ); } LoginUser loginUser = (LoginUser) authenticate.getPrincipal(); String userId = loginUser.getUser().getId().toString(); String token = JwtUtil.createJWT(userId); redisCache.setCacheObject("bloglogin:" +userId,loginUser); UserInfoVo userInfoVo = BeanCopyUtils.copyBean(loginUser.getUser(), UserInfoVo.class); BlogUserLoginVo blogUserLoginVo = new BlogUserLoginVo (token,userInfoVo); return ResponseResult.okResult(blogUserLoginVo); } }
UserDetailsService实现类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package com.sangeng.service.impl;import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;import com.sangeng.dao.UserDao;import com.sangeng.domain.entity.LoginUser;import com.sangeng.domain.entity.User;import org.apache.commons.lang3.StringUtils;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.security.core.userdetails.UserDetails;import org.springframework.security.core.userdetails.UserDetailsService;import org.springframework.security.core.userdetails.UsernameNotFoundException;import org.springframework.stereotype.Service;import java.util.Objects;@Service public class UserDetailsServiceImpl implements UserDetailsService { @Autowired private UserDao userDao; @Override public UserDetails loadUserByUsername (String userName) throws UsernameNotFoundException { LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper <>(); wrapper.eq(StringUtils.isNoneEmpty(userName),User::getUserName, userName); User user = userDao.selectOne(wrapper); if (Objects.isNull(user)) { throw new RuntimeException ("用户名或密码错误" ); } return new LoginUser (user); } }
UserDetails
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 package com.sangeng.domain.entity;import com.alibaba.fastjson.annotation.JSONField;import lombok.Data;import lombok.NoArgsConstructor;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.security.core.GrantedAuthority;import org.springframework.security.core.authority.SimpleGrantedAuthority;import org.springframework.security.core.userdetails.UserDetails;import java.util.Collection;import java.util.List;import java.util.stream.Collectors;@Data @NoArgsConstructor public class LoginUser implements UserDetails { @Autowired private User user; public LoginUser (User user) { this .user = user; } @Override public Collection<? extends GrantedAuthority > getAuthorities() { return null ; } @Override public String getPassword () { return user.getPassword(); } @Override public String getUsername () { return user.getUserName(); } @Override public boolean isAccountNonExpired () { return true ; } @Override public boolean isAccountNonLocked () { return true ; } @Override public boolean isCredentialsNonExpired () { return true ; } @Override public boolean isEnabled () { return true ; } }
JWT认证过滤器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 package com.sangeng.filter;import com.alibaba.fastjson.JSON;import com.sangeng.domain.common.ResponseResult;import com.sangeng.domain.entity.LoginUser;import com.sangeng.domain.enums.AppHttpCodeEnum;import com.sangeng.utils.JwtUtil;import com.sangeng.utils.RedisCache;import com.sangeng.utils.WebUtils;import io.jsonwebtoken.Claims;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;import org.springframework.security.core.context.SecurityContextHolder;import org.springframework.stereotype.Component;import org.springframework.util.StringUtils;import org.springframework.web.filter.OncePerRequestFilter;import javax.servlet.FilterChain;import javax.servlet.ServletException;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;import java.util.Objects;@Component public class JwtAuthenticationTokenFilter extends OncePerRequestFilter { @Autowired private RedisCache redisCache; @Override protected void doFilterInternal (HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException { String token = request.getHeader("token" ); if (!StringUtils.hasText(token)) { filterChain.doFilter(request, response); return ; } String userId; Claims claims = null ; try { claims = JwtUtil.parseJWT(token); } catch (Exception e) { e.printStackTrace(); ResponseResult result = ResponseResult.errorResult(AppHttpCodeEnum.NEED_LOGIN); WebUtils.renderString(response, JSON.toJSONString(result)); } userId = claims.getSubject(); String redisKey = "bloglogin:" + userId; LoginUser loginUser = redisCache.getCacheObject(redisKey); if (Objects.isNull(loginUser)) { ResponseResult result = ResponseResult.errorResult(AppHttpCodeEnum.NEED_LOGIN); WebUtils.renderString(response, JSON.toJSONString(result)); } UsernamePasswordAuthenticationToken usernamePasswordAuthenticationToken = new UsernamePasswordAuthenticationToken (loginUser, null , null ); SecurityContextHolder.getContext().setAuthentication(usernamePasswordAuthenticationToken); filterChain.doFilter(request, response); } }
springSecurity配置类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 package com.sangeng.config;import com.sangeng.filter.JwtAuthenticationTokenFilter;import com.sangeng.handle.security.AccessDeniedHandlerImpl;import com.sangeng.handle.security.AuthenticationEntryPointImpl;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.security.authentication.AuthenticationManager;import org.springframework.security.config.annotation.web.builders.HttpSecurity;import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;import org.springframework.security.config.http.SessionCreationPolicy;import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;import org.springframework.security.crypto.password.PasswordEncoder;import org.springframework.security.web.authentication.AuthenticationFailureHandler;import org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter;@Configuration public class SecurityConfig extends WebSecurityConfigurerAdapter { @Autowired private AccessDeniedHandlerImpl accessDeniedHandler; @Autowired private AuthenticationEntryPointImpl authenticationEntryPoint; @Autowired private JwtAuthenticationTokenFilter jwtAuthenticationTokenFilter; @Bean public PasswordEncoder passwordEncoder () { return new BCryptPasswordEncoder (); } @Override protected void configure (HttpSecurity http) throws Exception { http .csrf().disable() .sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS) .and() .authorizeRequests() .antMatchers("/login" ).anonymous() .antMatchers("/link/getAllLink" ).authenticated() .anyRequest().permitAll(); http.addFilterBefore(jwtAuthenticationTokenFilter,UsernamePasswordAuthenticationFilter.class); http.exceptionHandling() .accessDeniedHandler(accessDeniedHandler) .authenticationEntryPoint(authenticationEntryPoint); http.cors(); } @Bean @Override public AuthenticationManager authenticationManagerBean () throws Exception { return super .authenticationManagerBean(); } }
博客前台模块-异常处理 认证授权的异常处理 主要处理业务层的异常
权限认证失败处理器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package com.sangeng.handle.security;import com.alibaba.fastjson.JSON;import com.sangeng.domain.common.ResponseResult;import com.sangeng.domain.enums.AppHttpCodeEnum;import com.sangeng.utils.WebUtils;import org.springframework.http.HttpStatus;import org.springframework.security.access.AccessDeniedException;import org.springframework.security.web.access.AccessDeniedHandler;import org.springframework.stereotype.Component;import javax.servlet.ServletException;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;@Component public class AccessDeniedHandlerImpl implements AccessDeniedHandler { @Override public void handle (HttpServletRequest request, HttpServletResponse response, AccessDeniedException accessDeniedException) throws IOException, ServletException { accessDeniedException.printStackTrace(); ResponseResult result = ResponseResult.errorResult(AppHttpCodeEnum.NO_OPERATOR_AUTH); String json = JSON.toJSONString(result); WebUtils.renderString(response, json); } }
认证失败处理器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package com.sangeng.handle.security;import com.alibaba.fastjson.JSON;import com.sangeng.domain.common.ResponseResult;import com.sangeng.domain.enums.AppHttpCodeEnum;import com.sangeng.utils.WebUtils;import org.springframework.http.HttpStatus;import org.springframework.security.authentication.BadCredentialsException;import org.springframework.security.authentication.InsufficientAuthenticationException;import org.springframework.security.core.AuthenticationException;import org.springframework.security.web.AuthenticationEntryPoint;import org.springframework.stereotype.Component;import javax.servlet.ServletException;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;@Component public class AuthenticationEntryPointImpl implements AuthenticationEntryPoint { private Object result; @Override public void commence (HttpServletRequest request, HttpServletResponse response, AuthenticationException authException) throws IOException, ServletException { authException.printStackTrace(); if (authException instanceof InsufficientAuthenticationException){ result = ResponseResult.errorResult(AppHttpCodeEnum.NEED_LOGIN); } else if (authException instanceof BadCredentialsException){ result = ResponseResult.errorResult(AppHttpCodeEnum.LOGIN_ERROR.getCode(),authException.getMessage()); } else { result = ResponseResult.errorResult(AppHttpCodeEnum.SYSTEM_ERROR.getCode(),"认证或授权失败" ); } String json = JSON.toJSONString(result); WebUtils.renderString(response, json); } }
统一异常处理 主要处理controller层的异常
自定义异常处理器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package com.sangeng.handle.exception;import com.sangeng.domain.enums.AppHttpCodeEnum;public class SystemException extends RuntimeException { private int code; private String msg; public int getCode () { return code; } public String getMsg () { return msg; } public SystemException (AppHttpCodeEnum httpCodeEnum) { super (httpCodeEnum.getMsg()); this .code = httpCodeEnum.getCode(); this .msg = httpCodeEnum.getMsg(); } }
全局异常处理器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package com.sangeng.handle.exception;import com.sangeng.domain.common.ResponseResult;import com.sangeng.domain.enums.AppHttpCodeEnum;import lombok.extern.slf4j.Slf4j;import org.springframework.web.bind.annotation.ExceptionHandler;import org.springframework.web.bind.annotation.RestControllerAdvice;@Slf4j @RestControllerAdvice public class GlobalExceptionHandler extends RuntimeException { @ExceptionHandler(SystemException.class) public ResponseResult exceptionHandler (SystemException e) { log.error("出现了异常:{}" ,e); return ResponseResult.errorResult(e.getCode(), e.getMsg()); } @ExceptionHandler(Exception.class) public ResponseResult exceptionHandler (Exception e) { log.error("出现了异常:{}" ,e); return ResponseResult.errorResult(AppHttpCodeEnum.SYSTEM_ERROR.getCode(), e.getMessage()); } }
博客前台模块-退出功能 接口分析
思路分析 直接从SecurityContextHolder中获取登录用户,然后拿到用户ID,删除redis中相关用户ID
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override public ResponseResult logout () { Authentication authentication = SecurityContextHolder.getContext().getAuthentication(); LoginUser loginUser = (LoginUser) authentication.getPrincipal(); Long userId = loginUser.getUser().getId(); redisCache.deleteObject("bloglogin:" +userId); return ResponseResult.okResult(); }
注意在配置类中添加
让原本的Sringsecurity的退出登录方法失效
1 2 3 4 5 6 .antMatchers("/login" ).anonymous() .antMatchers("/logout" ).authenticated() http.logout().disable();
博客前台模块-评论列表* 接口分析
思路分析 先查询所有根评论,再对已有的根评论,再去查询子评论
根评论 根据条件分页查询根评论的记录 但是创作人的姓名和回复某个人的姓名没有封装,所以需要对评论Vo再进行封装,注意要判断如果(回复:姓名)的id是-1的话,这个评论是根评论,所以不需要封装(回复:姓名)姓名 反之需要
子评论 对根评论的集合再进行封装,根据传入的某个评论id,然后去查询得到所有根评论为这个id的集合,然后对其(名字 回复:名字)名字进行封装
得到所有评论集合
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 package com.sangeng.service.impl;import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;import com.baomidou.mybatisplus.extension.plugins.pagination.Page;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;import com.sangeng.dao.CommentDao;import com.sangeng.domain.common.ResponseResult;import com.sangeng.domain.constants.SystemCanstants;import com.sangeng.domain.entity.Comment;import com.sangeng.domain.vo.CommentVo;import com.sangeng.domain.vo.PageVo;import com.sangeng.service.CommentService;import com.sangeng.service.UserService;import com.sangeng.utils.BeanCopyUtils;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import java.util.Comparator;import java.util.List;import java.util.stream.Collectors;@Service("commentService") public class CommentServiceImpl extends ServiceImpl <CommentDao, Comment> implements CommentService { @Autowired private UserService userService; @Override public ResponseResult commentList (Long articleId, Integer pageNum, Integer pageSize) { LambdaQueryWrapper<Comment> commentLambdaQueryWrapper = new LambdaQueryWrapper <>(); commentLambdaQueryWrapper.eq(articleId!=null &&articleId>0 ,Comment::getArticleId,articleId); commentLambdaQueryWrapper.eq(Comment::getRootId, SystemCanstants.COMMENT_ROOT); Page<Comment> page = new Page <>(pageNum,pageSize); page = page(page,commentLambdaQueryWrapper); List<Comment> comments = page.getRecords(); comments = comments.stream() .sorted(Comparator.comparing(Comment::getCreateTime).reversed()) .collect(Collectors.toList()); List<CommentVo> commentVos = toCommentVos(comments); commentVos = commentVos.stream().map(commentVo -> { List<CommentVo> children = getChildren(commentVo.getId()); commentVo.setChildren(children); return commentVo; }).collect(Collectors.toList()); return ResponseResult.okResult(new PageVo (commentVos,page.getTotal())); } private List<CommentVo> getChildren (Long id) { LambdaQueryWrapper<Comment> commentLambdaQueryWrapper = new LambdaQueryWrapper <>(); commentLambdaQueryWrapper.eq(Comment::getRootId,id); commentLambdaQueryWrapper.orderByDesc(Comment::getCreateTime); List<Comment> comments = list(commentLambdaQueryWrapper); List<CommentVo> commentVos = toCommentVos(comments); return commentVos; } private List<CommentVo> toCommentVos (List<Comment> comments) { List<CommentVo> commentVos = BeanCopyUtils.copyBeanList(comments, CommentVo.class); commentVos = commentVos.stream().map(commentVo -> { commentVo.setUsername(userService.getById(commentVo.getCreateBy()).getNickName()); if (commentVo.getToCommentUserId()!=-1 ) { String nickName = userService.getById(commentVo.getToCommentUserId()).getNickName(); commentVo.setToCommentUserName(nickName); } return commentVo; }).collect(Collectors.toList()); return commentVos; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package com.sangeng.domain.vo;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import java.util.Date;import java.util.List;@Data @NoArgsConstructor @AllArgsConstructor public class CommentVo { private Long id; private Long articleId; private Long rootId; private String content; private Long toCommentUserId; private String toCommentUserName; private Long toCommentId; private Long createBy; private Date createTime; private String username; private List<CommentVo> children; }
博客前台模块-发送评论* 发送文章评论 接口分析
思路分析 可以直接调用mp的save方法将信息保存,但是有的信息不能添加,比如更新人,插入时间等。
利用mp的自动填充可以实现,然后再评论表中的属性上添加@TableField(fill = FieldFill.INSERT)注解,代表再添加时自动填充
获取更新人id,可以在securitycontextholder中来获取,后面还有好多需要这个,直接封装工具类
代码实现 1 2 3 4 5 6 7 8 @Override public ResponseResult addComment (Comment comment) { if (!StringUtils.hasText(comment.getContent())) { throw new SystemException (AppHttpCodeEnum.CONTENT_NOT_NULL); } save(comment); return ResponseResult.okResult(); }
utils
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package com.sangeng.utils;import com.sangeng.domain.entity.LoginUser;import org.springframework.security.core.Authentication;import org.springframework.security.core.context.SecurityContextHolder;public class SecurityUtils { public static LoginUser getLoginUser () { return (LoginUser) getAuthentication().getPrincipal(); } public static Authentication getAuthentication () { return SecurityContextHolder.getContext().getAuthentication(); } public static Boolean isAdmin () { Long id = getLoginUser().getUser().getId(); return id != null && 1L == id; } public static Long getUserId () { return getLoginUser().getUser().getId(); } }
mp自动填充
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package com.sangeng.handle.mp;import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;import com.sangeng.utils.SecurityUtils;import org.apache.ibatis.reflection.MetaObject;import org.springframework.stereotype.Component;import java.util.Date;@Component public class MyMetaObjectHandler implements MetaObjectHandler { @Override public void insertFill (MetaObject metaObject) { Long userId = null ; userId = SecurityUtils.getUserId(); this .setFieldValByName("createTime" , new Date (), metaObject); this .setFieldValByName("createBy" ,userId , metaObject); this .setFieldValByName("updateTime" , new Date (), metaObject); this .setFieldValByName("updateBy" , userId, metaObject); } @Override public void updateFill (MetaObject metaObject) { this .setFieldValByName("updateTime" , new Date (), metaObject); this .setFieldValByName(" " , SecurityUtils.getUserId(), metaObject); } }
实体类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 package com.sangeng.domain.entity;import java.util.Date;import java.io.Serializable;import com.baomidou.mybatisplus.annotation.FieldFill;import com.baomidou.mybatisplus.annotation.TableField;import com.baomidou.mybatisplus.annotation.TableName;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@SuppressWarnings("serial") @Data @NoArgsConstructor @AllArgsConstructor @TableName("sg_comment") public class Comment { private Long id; private String type; private Long articleId; private Long rootId; private String content; private Long toCommentUserId; private Long toCommentId; @TableField(fill = FieldFill.INSERT) private Long createBy; @TableField(fill = FieldFill.INSERT) private Date createTime; @TableField(fill = FieldFill.INSERT_UPDATE) private Long updateBy; @TableField(fill = FieldFill.INSERT_UPDATE) private Date updateTime; private Integer delFlag; }
发送友链评论 接口分析
思路分析 根据接口可以查看到,和文章评论共用一个接口,在接口的参数上可以加一个文章或者友链的type,然后再实现类里面对文章id(因为再评论表里面有个type分成友链和文章评论)和type类型进行判断
实现代码 1 2 3 4 5 6 7 @GetMapping("/linkCommentList") public ResponseResult linkCommentList (Integer pageNum,Integer pageSize) { return commentService.commentList(SystemCanstants.LINK_COMMENT,null ,pageNum,pageSize); }
1 2 ResponseResult commentList (String type,Long articleId, Integer pageNum, Integer pageSize) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Override public ResponseResult commentList (String type, Long articleId, Integer pageNum, Integer pageSize) { LambdaQueryWrapper<Comment> commentLambdaQueryWrapper = new LambdaQueryWrapper <>(); commentLambdaQueryWrapper.eq(articleId!=null &&articleId>0 ,Comment::getArticleId,articleId); commentLambdaQueryWrapper.eq(Comment::getRootId, SystemCanstants.COMMENT_ROOT); commentLambdaQueryWrapper.eq(Comment::getType,type); Page<Comment> page = new Page <>(pageNum,pageSize); page = page(page,commentLambdaQueryWrapper); }
博客前台模块-个人信息 接口分析
思路分析 此接口需要再登录之后才能访问,直接获取Security里面的用户id,根据id查询相关信息,并且封装Vo
代码实现 在SecurityConfig中配置
1 2 .antMatchers("/user/userInfo" ).authenticated()
1 2 3 4 5 6 7 8 9 10 11 12 13 @Override public ResponseResult userInfo () { String userId = SecurityUtils.getUserId().toString(); User user = getById(userId); UserInfoVo userInfoVo = BeanCopyUtils.copyBean(user, UserInfoVo.class); return ResponseResult.okResult(userInfoVo); }
博客前台模块-文件上传* 先解决头像上传
为什么使用OSS?
因为如果把图片视频等文件上传到自己的应用的Web服务器的某个目录下,在读取图片的时候会占用比较多的资源。影响应用服务器的性能。所以我们一般使用OSS(Object Storage Service对象存储服务)存储图片或视频
OSS
用户—上传图片–>Web服务器 —读取—> 用户
接口分析
思路分析 先将图片上传到web服务器,然后传到oss,用户可直接浏览图片 注意上传需要multipart/form-data; 接口参数为 MultipartFile
需要判断文件类型的合法性和文件类型的大小是否合法,并且将文件名修改为日期+uuid+文件名后缀 密钥什么的保存在yml中,通过
代码@ConfigurationProperties(prefix = “myoss”)获取yml中信息,注意实体属性名需要和yml里面的一样 哦对,一定要加@Data注解,要不然属性值获取不了
代码实现 controller
1 2 3 4 5 @PostMapping("upload") public ResponseResult upload (MultipartFile img) { return upLoadService.upLoadImg(img); }
serviceImpl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 package com.sangeng.service.impl;import com.google.gson.Gson;import com.qiniu.common.QiniuException;import com.qiniu.http.Response;import com.qiniu.storage.Configuration;import com.qiniu.storage.Region;import com.qiniu.storage.UploadManager;import com.qiniu.storage.model.DefaultPutRet;import com.qiniu.util.Auth;import com.sangeng.domain.common.ResponseResult;import com.sangeng.domain.constants.SystemCanstants;import com.sangeng.domain.enums.AppHttpCodeEnum;import com.sangeng.handle.exception.SystemException;import com.sangeng.service.UpLoadService;import com.sangeng.utils.PathUtils;import lombok.Data;import org.springframework.beans.factory.annotation.Value;import org.springframework.boot.context.properties.ConfigurationProperties;import org.springframework.stereotype.Service;import org.springframework.web.multipart.MultipartFile;import java.io.FileInputStream;import java.io.InputStream;@Service @Data @ConfigurationProperties(prefix = "myoss") public class UpLoadServiceImpl implements UpLoadService { private String accessKey; private String secretKey; private String bucket; private String yuming; @Override public ResponseResult upLoadImg (MultipartFile img) { String originalFilename = img.getOriginalFilename(); long fileSize = img.getSize(); if (!originalFilename.endsWith(".png" )&&!originalFilename.endsWith(".jpg" )) { throw new SystemException (AppHttpCodeEnum.FILE_TYPE_ERROR); } if (fileSize > 2 * 1024 * 1024 ) { throw new SystemException (AppHttpCodeEnum.FILE_SIZE_ERROR); } String filePath = PathUtils.generateFilePath(originalFilename); String url = uploadOss(img,filePath); return ResponseResult.okResult(url); } public String uploadOss (MultipartFile img,String filePath) { Configuration cfg = new Configuration (Region.region1()); cfg.resumableUploadAPIVersion = Configuration.ResumableUploadAPIVersion.V2; UploadManager uploadManager = new UploadManager (cfg); String key = filePath; try { InputStream xxinputStream = img.getInputStream(); Auth auth = Auth.create(accessKey, secretKey); String upToken = auth.uploadToken(bucket); try { Response response = uploadManager.put(xxinputStream, key, upToken, null , null ); DefaultPutRet putRet = new Gson ().fromJson(response.bodyString(), DefaultPutRet.class); System.out.println("上传成功! 生成的key是: " + putRet.key); System.out.println("上传成功! 生成的hash是: " + putRet.hash); return yuming+key; } catch (QiniuException ex) { Response r = ex.response; System.err.println(r.toString()); try { System.err.println(r.bodyString()); } catch (QiniuException ex2) { } } } catch (Exception e) { } return "www:" ; } }
工具包(生成文件名)日期+uuid+后缀
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com.sangeng.utils;import java.text.SimpleDateFormat;import java.util.Date;import java.util.UUID;public class PathUtils { public static String generateFilePath (String fileName) { SimpleDateFormat sdf = new SimpleDateFormat ("yyyy/MM/dd/" ); String datePath = sdf.format(new Date ()); String uuid = UUID.randomUUID().toString().replaceAll("-" , "" ); int index = fileName.lastIndexOf("." ); String fileType = fileName.substring(index); return new StringBuilder ().append(datePath).append(uuid).append(fileType).toString(); } }
更新个人信息 接口分析
思路分析 将数据封装到请求体内,后端接口从响应体中拿直接根据id进行更新
代码实现 博客前台模块-注册信息 接口分析
思路分析 进行非空判断
进行是否重复判断
进行密码加密
存储数据库
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 @Autowired private PasswordEncoder passwordEncoder; @Override public ResponseResult register (User user) { if (!StringUtils.hasText(user.getUserName())){ throw new SystemException (AppHttpCodeEnum.USERNAME_NOT_NULL); } if (!StringUtils.hasText(user.getPassword())){ throw new SystemException (AppHttpCodeEnum.PASSWORD_NOT_NULL); } if (!StringUtils.hasText(user.getEmail())){ throw new SystemException (AppHttpCodeEnum.EMAIL_NOT_NULL); } if (!StringUtils.hasText(user.getNickName())){ throw new SystemException (AppHttpCodeEnum.NICKNAME_NOT_NULL); } if (userNameExist(user.getUserName())){ throw new SystemException (AppHttpCodeEnum.USERNAME_EXIST); } if (NickNameExist(user.getNickName())){ throw new SystemException (AppHttpCodeEnum.NICKNAME_EXIST); } if (EmailExist(user.getEmail())){ throw new SystemException (AppHttpCodeEnum.EMAIL_EXIST); } String encodePassword = passwordEncoder.encode(user.getPassword()); user.setPassword(encodePassword); save(user); return ResponseResult.okResult(); } private boolean userNameExist (String userName) { LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper <>(); queryWrapper.eq(User::getUserName,userName); boolean result = count(queryWrapper) > 0 ; return result; } private boolean NickNameExist (String nickName) { LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper <>(); queryWrapper.eq(User::getNickName,nickName); boolean result = count(queryWrapper) > 0 ; return result; } private boolean EmailExist (String email) { LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper <>(); queryWrapper.eq(User::getEmail,email); boolean result = count(queryWrapper) > 0 ; return result; }
博客前台模块-日志记录* AOP实现日志记录
需求
思路分析 相当于是对原有的功能进行增强。并且是批量的增强,这个时候就非常适合用AOP来进行实现。
代码实现 利用注解来实现
注解
1 2 3 4 5 6 @Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) public @interface SystemLog { String businessName () ; }
切面类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 @Component @Aspect @Slf4j public class LogAspect { @Pointcut("@annotation(com.sangeng.annoation.SystemLog)") public void pt () { } @Around("pt()") public Object inform (ProceedingJoinPoint joinPoint) throws Throwable { Object rel; try { handleBefore(joinPoint); rel = joinPoint.proceed(); handleAfter(rel); } finally { log.info("=======End=======" + System.lineSeparator()); } return rel; } private void handleBefore (ProceedingJoinPoint joinPoint) throws UnknownHostException { ServletRequestAttributes requestAttributeEvent = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); HttpServletRequest request = requestAttributeEvent.getRequest(); MethodSignature signature = (MethodSignature) joinPoint.getSignature(); String businessName = signature.getMethod().getAnnotation(SystemLog.class).businessName(); log.info("=======Start=======" ); log.info("URL : {}" , request.getRequestURL()); log.info("BusinessName : {}" , businessName); log.info("HTTP Method : {}" ,request.getMethod()); log.info("Class Method : {}.{}" , signature.getDeclaringTypeName(), signature.getMethod().getName()); log.info("IP : {}" , request.getRemoteHost()); log.info("Request Args : {}" , JSON.toJSONString(joinPoint.getArgs())); } private void handleAfter (Object object) { log.info("Response : {}" , JSON.toJSONString(object)); } }
接口
1 2 3 4 5 6 @PutMapping("userInfo") @SystemLog(businessName = "更新用户信息") public ResponseResult updateUserInfo (@RequestBody User user) { return userService.updateUserInfo(user); }
实现
博客前台模块-更新浏览量* 需求 在用户浏览博文时要实现对应博客浏览量的增加
思路分析 我们只需要在每次用户浏览博客时更新对应的浏览数即可。 但是如果直接操作博客表的浏览量的话,在并发量大的情况下会出现什么问题呢? 如何去优化呢?
(因为要更新浏览量的话,会加写锁,只能一个用户占用一条记录,其他不能修改,这就得考虑并发)
①在应用启动时把博客的浏览量存储到redis中
②更新浏览量时去更新redis中的数据
③每隔10分钟把Redis中的浏览量更新到数据库中
④读取文章浏览量时从redis读取
铺垫知识 ①CommandLineRunner实现项目启动时预处理 实现此接口,并加入容器
③定时任务
定时任务的实现方式有很多,比如XXL-Job等。但是其实核心功能和概念都是类似的,很多情况下只是调 用的API不同而已。 这里就先用SpringBoot为我们提供的定时任务的API来实现一个简单的定时任务,让大家先对定时任务 里面的一些核心概念有个大致的了解。 实现步骤 ① 使用@EnableScheduling注解开启定时任务功能 我们可以在配置类上加上@EnableScheduling
1 2 3 4 5 6 7 8 @SpringBootApplication @MapperScan("com.sangeng.mapper") @EnableScheduling public class SanGengBlogApplication {public static void main (String[] args) {SpringApplication.run(SanGengBlogApplication.class,args); } }
确定定时任务执行代码,并配置任务执行时间 使用@Scheduled注解标识需要定时执行的代码。注解的cron属性相当于是任务的执行时间。目前可以 使用 0/5 * * * * ? 进行测试,代表从0秒开始,每隔5秒执行一次。 注意:对应的bean要注入容器,否则不会生效。
1 2 3 4 5 6 7 8 9 @Component public class TestJob {@Scheduled(cron = "0/5 * * * * ?") public void testJob () {System.out.println("定时任务执行了" ); } }
corn定时任务表达式
接口设计
代码实现 将数据库存到redis中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package com.sangeng.runner;import com.sangeng.dao.ArticleDao;import com.sangeng.domain.constants.SystemCanstants;import com.sangeng.domain.entity.Article;import com.sangeng.service.ArticleService;import com.sangeng.utils.RedisCache;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.CommandLineRunner;import org.springframework.stereotype.Component;import java.util.List;import java.util.Map;import java.util.function.Function;import java.util.stream.Collectors;@Component public class ViewCountRunner implements CommandLineRunner { @Autowired private ArticleDao articleDao; @Autowired private RedisCache redisCache; @Override public void run (String... args) throws Exception { List<Article> articles = articleDao.selectList(null ); Map<String, Integer> viewCounts = articles.stream().collect(Collectors.toMap(article -> article.getId().toString(), article -> article.getViewCount().intValue())); redisCache.setCacheMap(SystemCanstants.VIEW_COUNT_KEY,viewCounts); } }
更新浏览量数据到redis中
1 2 3 4 5 6 7 8 @Override public ResponseResult updateViewCount (Long id) { redisCache.updateCacheMap(SystemCanstants.VIEW_COUNT_KEY,id.toString(),SystemCanstants.UPDATE_VIEW_COUNT); return ResponseResult.okResult(); }
redisCache
1 2 3 4 5 6 7 8 9 public void updateCacheMap (final String key, final String hashKey, Integer value) { redisTemplate.opsForHash().increment(key,hashKey,value); }
将redis中数据定时推送到数据库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package com.sangeng.job;import com.sangeng.domain.constants.SystemCanstants;import com.sangeng.domain.entity.Article;import com.sangeng.service.ArticleService;import com.sangeng.utils.RedisCache;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.scheduling.annotation.Scheduled;import org.springframework.stereotype.Component;import java.util.List;import java.util.Map;import java.util.stream.Collectors;@Component public class UpdateViewCount { @Autowired private RedisCache redisCache; @Autowired private ArticleService articleService; @Scheduled(cron = "0 0/5 * * * ? ") public void updateViewCount () { Map<String, Integer> viewCountMap = redisCache.getCacheMap(SystemCanstants.VIEW_COUNT_KEY); List<Article> articles = viewCountMap.entrySet().stream() .map(vv -> { Article article = new Article (); String id = vv.getKey(); Integer viewCount = vv.getValue(); article.setId(Integer.valueOf(id).longValue()); article.setViewCount(viewCount.longValue()); return article; }).collect(Collectors.toList()); articleService.updateBatchById(articles); } }
在redis中查看浏览量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 @Override public ResponseResult hotArticleList () { Map<String, Integer> viewCountMap = redisCache.getCacheMap(SystemCanstants.VIEW_COUNT_KEY); List<Article> articles = viewCountMap.entrySet().stream() .map(vv -> { Article article = new Article (); String id = vv.getKey(); Integer viewCount = vv.getValue(); article.setId(Integer.valueOf(id).longValue()); article.setViewCount(viewCount.longValue()); return article; }).collect(Collectors.toList()); updateBatchById(articles); LambdaQueryWrapper<Article> lambdaQueryWrapper = new LambdaQueryWrapper (); lambdaQueryWrapper.eq(Article::getStatus, SystemCanstants.ARTICLE_STATUS_NORMAL); lambdaQueryWrapper.orderByDesc(Article::getViewCount); Page<Article> page = new Page (SystemCanstants.ARTICLE_STATUS_CURRENT, SystemCanstants.ARTICLE_STATUS_SIZE); page(page, lambdaQueryWrapper); List<Article> hotArticleList = page.getRecords(); List<HotArticleVo> hotArticleVos = BeanCopyUtils.copyBeanList(hotArticleList, HotArticleVo.class); return ResponseResult.okResult(hotArticleVos); } @Override public ResponseResult articleList (Long pageNum,Long pageSize,Long categoryId) { LambdaQueryWrapper<Article> articleLambdaQueryWrapper = new LambdaQueryWrapper <>(); articleLambdaQueryWrapper.eq(Article::getStatus,SystemCanstants.ARTICLE_STATUS_NORMAL); articleLambdaQueryWrapper.orderByDesc(Article::getIsTop); articleLambdaQueryWrapper.eq(Objects.nonNull(categoryId)&&categoryId>0 ,Article::getCategoryId,categoryId); Page<Article> articlePage = new Page <>(pageNum,pageSize); articlePage = page(articlePage,articleLambdaQueryWrapper); List<Article> articles = articlePage.getRecords(); articles = articles.stream().map(article -> { Integer viewCount = redisCache.getCacheMapValue(SystemCanstants.VIEW_COUNT_KEY, article.getId().toString()); article.setViewCount(viewCount.longValue()); article.setCategoryName(categoryService.getById(article.getCategoryId()).getName()); return article; }).collect(Collectors.toList()); List<ArticleListVo> articleListVos = BeanCopyUtils.copyBeanList(articlePage.getRecords(), ArticleListVo.class); PageVo pageVO = new PageVo (articleListVos, articlePage.getTotal()); return ResponseResult.okResult(pageVO); } @Override public ResponseResult getArticleDetail (Long id) { ArticleDetailVo articleDetailVo = null ; if (Objects.nonNull(id) && id > 0 ) { Article article = this .getById(id); Integer viewCount = redisCache.getCacheMapValue(SystemCanstants.VIEW_COUNT_KEY, id.toString()); article.setViewCount(viewCount.longValue()); Long categoryId = article.getCategoryId(); Category category = categoryService.getById(categoryId); if (category!=null ) { article.setCategoryName(category.getName()); articleDetailVo = BeanCopyUtils.copyBean(article, ArticleDetailVo.class); } } return ResponseResult.okResult(articleDetailVo); }
Swagger 引入POM依赖
1 2 3 4 5 6 7 8 <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger-ui</artifactId> </dependency>
在启动类添加@EnableSwagger2注解
Controller层
1 2 3 @Api(tags = "用户信息",description = "用户信息相关接口") public class UserController {}
接口
1 2 @ApiOperation(value = "更新个人信息",notes = "获取个人的相关信息")
接口参数
1 @ApiImplicitParam(name = "user",value = "更新的用户信息")
实体类,最好封装前端传过来的参数 dto
1 2 @ApiModel(value = "增加评论DTO") public class AddCommentDto {}
实体类属性
1 2 3 @ApiModelProperty("0代表文章评论,1代表友链评论") private String type;
文档信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package com.sangeng.config;import com.google.common.base.Predicates;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import springfox.documentation.builders.ApiInfoBuilder;import springfox.documentation.builders.PathSelectors;import springfox.documentation.builders.RequestHandlerSelectors;import springfox.documentation.service.ApiInfo;import springfox.documentation.service.Contact;import springfox.documentation.spi.DocumentationType;import springfox.documentation.spring.web.plugins.Docket;import springfox.documentation.swagger2.annotations.EnableSwagger2;@Configuration @EnableSwagger2 public class SwaggerConfig { @Bean public Docket customDocket () { return new Docket (DocumentationType.SWAGGER_2) .apiInfo(apiInfo()) .select() .apis(RequestHandlerSelectors.basePackage("com.sangeng.controller" )) .paths(Predicates.not(PathSelectors.regex("/error.*" ))) .build(); } private ApiInfo apiInfo () { Contact contact = new Contact ("久违" , "https://mykang2003.github.io" , "501858029@qq.com" ); return new ApiInfoBuilder () .title("博客前台文档" ) .description("博客前台文档" ) .contact(contact) .version("1.1.1" ) .build(); } }
博客后台模块-测试 博客后台模块-登录 接口分析
解决思路
代码实现 jwt认证
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 package com.sangeng.filter;import com.alibaba.fastjson.JSON;import com.sangeng.domain.common.ResponseResult;import com.sangeng.domain.entity.LoginUser;import com.sangeng.domain.enums.AppHttpCodeEnum;import com.sangeng.utils.JwtUtil;import com.sangeng.utils.RedisCache;import com.sangeng.utils.WebUtils;import io.jsonwebtoken.Claims;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;import org.springframework.security.core.context.SecurityContextHolder;import org.springframework.stereotype.Component;import org.springframework.util.StringUtils;import org.springframework.web.filter.OncePerRequestFilter;import javax.servlet.FilterChain;import javax.servlet.ServletException;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;import java.util.Objects;@Component public class JwtAuthenticationTokenFilter extends OncePerRequestFilter { @Autowired private RedisCache redisCache; @Override protected void doFilterInternal (HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException { String token = request.getHeader("token" ); if (!StringUtils.hasText(token)) { filterChain.doFilter(request, response); return ; } String userId; Claims claims = null ; try { claims = JwtUtil.parseJWT(token); } catch (Exception e) { e.printStackTrace(); ResponseResult result = ResponseResult.errorResult(AppHttpCodeEnum.NEED_LOGIN); WebUtils.renderString(response, JSON.toJSONString(result)); } userId = claims.getSubject(); String redisKey = "adminbloglogin:" + userId; LoginUser loginUser = redisCache.getCacheObject(redisKey); if (Objects.isNull(loginUser)) { ResponseResult result = ResponseResult.errorResult(AppHttpCodeEnum.NEED_LOGIN); WebUtils.renderString(response, JSON.toJSONString(result)); } UsernamePasswordAuthenticationToken usernamePasswordAuthenticationToken = new UsernamePasswordAuthenticationToken (loginUser, null , null ); SecurityContextHolder.getContext().setAuthentication(usernamePasswordAuthenticationToken); filterChain.doFilter(request, response); } }
登录接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 package com.sangeng.service.impl;import com.sangeng.domain.common.ResponseResult;import com.sangeng.domain.entity.LoginUser;import com.sangeng.domain.entity.User;import com.sangeng.domain.enums.AppHttpCodeEnum;import com.sangeng.domain.vo.BlogUserLoginVo;import com.sangeng.domain.vo.UserInfoVo;import com.sangeng.service.AdminBlogLoginService;import com.sangeng.utils.BeanCopyUtils;import com.sangeng.utils.JwtUtil;import com.sangeng.utils.RedisCache;import com.sangeng.utils.SecurityUtils;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.security.authentication.AuthenticationManager;import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;import org.springframework.security.core.Authentication;import org.springframework.stereotype.Service;import java.util.HashMap;import java.util.Map;import java.util.Objects;@Service public class AdminBlogLoginServiceImpl implements AdminBlogLoginService { @Autowired private RedisCache redisCache; @Autowired private AuthenticationManager authenticationManager; @Override public ResponseResult login (User user) { UsernamePasswordAuthenticationToken usernamePasswordAuthenticationToken = new UsernamePasswordAuthenticationToken (user.getUserName(),user.getPassword()); Authentication authenticate = authenticationManager.authenticate(usernamePasswordAuthenticationToken); if (Objects.isNull(authenticate)){ throw new RuntimeException ("用户名或密码错误" ); } LoginUser loginUser = (LoginUser) authenticate.getPrincipal(); String userId = loginUser.getUser().getId().toString(); String token = JwtUtil.createJWT(userId); redisCache.setCacheObject("adminbloglogin:" +userId,loginUser); Map<String,String> tokenMap = new HashMap <>(); tokenMap.put("token" ,token); return ResponseResult.okResult(tokenMap); } @Override public ResponseResult logout () { String userId = SecurityUtils.getUserId().toString(); redisCache.deleteObject("adminbloglogin:" +userId); return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS.getCode(),"注销成功" ); } }
userDetails和前面一样
*博客后台模块-后台权限控制 接口分析
思路分析 查询登录的用户的权限,角色,和用户的信息
获取登录的id,如果是管理员1,就直接查询管理员为1的权限,并且需要有菜单为C或者按钮为F的条件和权限正常的权限列表。如果是普通用户,就连表查询所对应的用户的权限,并且也要有C和F的条件和权限正常的
查询角色,如果是管理员直接返回admin,如果是普通用户,就去连表查询用户的角色的名称
代码实现 查询权限信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package com.sangeng.service.impl;import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;import com.sangeng.dao.MenuDao;import com.sangeng.domain.constants.SystemCanstants;import com.sangeng.domain.entity.Menu;import com.sangeng.service.MenuService;import org.springframework.stereotype.Service;import java.util.List;import java.util.stream.Collectors;@Service public class MenuServiceImpl extends ServiceImpl <MenuDao, Menu> implements MenuService { @Override public List<String> selectPermsByUserId (Long id) { if (id == 1L ){ LambdaQueryWrapper<Menu> wrapper = new LambdaQueryWrapper <>(); wrapper.in(Menu::getMenuType, SystemCanstants.TYPE_MENU,SystemCanstants.TYPE_BUTTON); wrapper.eq(Menu::getStatus,SystemCanstants.MENU_STATUS_NORMAL); List<Menu> menus = list(wrapper); List<String> perms = menus.stream() .map(Menu::getPerms) .collect(Collectors.toList()); return perms; } List<String> otherPerms = getBaseMapper().selectPermsByOtherUserId(id); return otherPerms; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace="com.sangeng.dao.MenuDao" > <select id="selectPermsByOtherUserId" resultType="java.lang.String" > SELECT DISTINCT m.perms FROM `sys_user_role` ur LEFT JOIN `sys_role_menu` rm ON ur.`role_id` = rm.`role_id` LEFT JOIN `sys_menu` m ON m.`id` = rm.`menu_id` WHERE ur.`user_id` = #{userId} AND m.`menu_type` IN ('C' ,'F' ) AND m.`status` = 0 AND m.`del_flag` = 0 </select> </mapper>
查询角色信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package com.sangeng.service.impl;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;import com.sangeng.dao.RoleDao;import com.sangeng.domain.entity.Role;import com.sangeng.service.RoleService;import org.springframework.stereotype.Service;import java.util.ArrayList;import java.util.List;@Service public class RoleServiceImpl extends ServiceImpl <RoleDao, Role> implements RoleService { @Override public List<String> selectRoleKeyByUserId (Long id) { if (id == 1L ){ List<String> roleKeys = new ArrayList <>(); roleKeys.add("admin" ); return roleKeys; } List<String> otherRole = getBaseMapper().selectRoleKeyByOtherUserId(id); return otherRole; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace="com.sangeng.dao.RoleDao" > <!--MenuMapper接口的映射文件--> <select id="selectRoleKeyByOtherUserId" resultType="java.lang.String" > SELECT r.`role_key` FROM `sys_user_role` ur LEFT JOIN `sys_role` r ON ur.`role_id` = r.`id` WHERE ur.`user_id` = #{userId} AND r.`status` = 0 AND r.`del_flag` = 0 </select> </mapper>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @GetMapping("/getInfo") public ResponseResult<AdminUserInfoVo> getInfo () { LoginUser loginUser = SecurityUtils.getLoginUser(); List<String> perms = menuService.selectPermsByUserId(loginUser.getUser().getId()); List<String> roleKeyList = roleService.selectRoleKeyByUserId(loginUser.getUser().getId()); User user = loginUser.getUser(); UserInfoVo userInfoVo = BeanCopyUtils.copyBean(user, UserInfoVo.class); AdminUserInfoVo adminUserInfoVo = new AdminUserInfoVo (perms,roleKeyList,userInfoVo); return ResponseResult.okResult(adminUserInfoVo); }
*动态路由 实现了这个动态路由功能之后,就能在浏览器web页面登录进博客管理后台了,小期待不是
接口分析 接口设计。后台系统需要能实现不同的用户权限可以看到不同的功能,即左侧的导航栏
请求方式
请求地址
请求头
GET
/getRouters
需要token请求头
响应格式如下: 前端为了实现动态路由的效果,需要后端有接口能返回用户所能访问的菜单数据。注意: 返回的菜单数据需要体现父子菜单的层级关系
如果用户id为1代表管理员,menus中需要有所有菜单类型为C或者M的,C表示菜单,M表示目录,状态为正常的,未被删除的权限
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 { "code" : 200 , "data" : { "menus" : [ { "children" : [ ] , "component" : "content/article/write/index" , "createTime" : "2022-01-08 11:39:58" , "icon" : "build" , "id" : 2023 , "menuName" : "写博文" , "menuType" : "C" , "orderNum" : "0" , "parentId" : 0 , "path" : "write" , "perms" : "content:article:writer" , "status" : "0" , "visible" : "0" } , { "children" : [ { "children" : [ ] , "component" : "system/user/index" , "createTime" : "2021-11-12 18:46:19" , "icon" : "user" , "id" : 100 , "menuName" : "用户管理" , "menuType" : "C" , "orderNum" : "1" , "parentId" : 1 , "path" : "user" , "perms" : "system:user:list" , "status" : "0" , "visible" : "0" } , { "children" : [ ] , "component" : "system/role/index" , "createTime" : "2021-11-12 18:46:19" , "icon" : "peoples" , "id" : 101 , "menuName" : "角色管理" , "menuType" : "C" , "orderNum" : "2" , "parentId" : 1 , "path" : "role" , "perms" : "system:role:list" , "status" : "0" , "visible" : "0" } , { "children" : [ ] , "component" : "system/menu/index" , "createTime" : "2021-11-12 18:46:19" , "icon" : "tree-table" , "id" : 102 , "menuName" : "菜单管理" , "menuType" : "C" , "orderNum" : "3" , "parentId" : 1 , "path" : "menu" , "perms" : "system:menu:list" , "status" : "0" , "visible" : "0" } ] , "createTime" : "2021-11-12 18:46:19" , "icon" : "system" , "id" : 1 , "menuName" : "系统管理" , "menuType" : "M" , "orderNum" : "1" , "parentId" : 0 , "path" : "system" , "perms" : "" , "status" : "0" , "visible" : "0" } ] } , "msg" : "操作成功" }
实现思路 先判断是不是管理员,先找出管理员的所有菜单,或者是普通用户的所具有的所有菜单
然后对这些菜单进行建树,先筛选出父菜单为0的,它就是第一层菜单,然后找到他的菜单id(设为第一层菜单id)。在遍历一遍集合,找出父菜单为第一层菜单id的所有菜单,将这个集合赋值给第一层菜单的children
实现代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Override public List<Menu> selectRouterMenuTreeByUserId (Long id) { MenuDao menuDao = getBaseMapper(); List<Menu> menus = null ; if (SecurityUtils.isAdmin()){ menus = menuDao.selectAllRouterMenu(); } else { menus = menuDao.selectOtherRouterMenuTreeByUserId(id); } List<Menu> menuTree = buildMenuTree(menus,0L ); return menuTree; } private List<Menu> buildMenuTree (List<Menu> menus, long parentId) { List<Menu> menuTree = menus.stream().filter(menu -> menu.getParentId().equals(parentId)) .map(menu -> menu.setChildren(getChildren(menu, menus))) .collect(Collectors.toList()); return menuTree; } private List<Menu> getChildren (Menu menu, List<Menu> menus) { List<Menu> childrenList = menus.stream() .filter(menu1 -> menu1.getParentId().equals(menu.getId())) .map(menu1 -> menu1.setChildren(getChildren(menu1, menus))) .collect(Collectors.toList()); return childrenList; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 package com.sangeng.domain.entity;import java.util.Date;import java.io.Serializable;import java.util.List;import com.baomidou.mybatisplus.annotation.TableField;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import com.baomidou.mybatisplus.annotation.TableId;import com.baomidou.mybatisplus.annotation.TableName;import lombok.experimental.Accessors;@SuppressWarnings("serial") @Data @AllArgsConstructor @NoArgsConstructor @TableName("sys_menu") @Accessors(chain = true) public class Menu { @TableId private Long id; private String menuName; private Long parentId; private Integer orderNum; private String path; private String component; private Integer isFrame; private String menuType; private String visible; private String status; private String perms; private String icon; private Long createBy; private Date createTime; private Long updateBy; private Date updateTime; private String remark; private String delFlag; @TableField(exist = false) private List<Menu> children; }
后端把long类型转换为String类型
1 2 3 SerializeConfig.globalInstance.put(Long.class, ToStringSerializer.instance);
分页total数是long,但是前端要显示数字,所以在前端拦截器地方,在配置一下,字符串转为Long类型
1 2 3 4 5 if (res.data.data && res.data.data.total) { res.data.data.total = parseInt(res.data.data.total) } return res.data.data
退出登录 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Override public ResponseResult logout () { String userId = SecurityUtils.getUserId().toString(); redisCache.deleteObject("adminbloglogin:" +userId); return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS.getCode(),"注销成功" ); } }
标签列表 查询标签 需求&接口设计
实现思路 根据标签名进行分页查询所有标签,然后封装VO返回
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override public ResponseResult<PageVo> pageTagList (Integer pageNum, Integer pageSize, TagListDto tagListDto) { LambdaQueryWrapper<Tag> tagLambdaQueryWrapper = new LambdaQueryWrapper <>(); tagLambdaQueryWrapper.like(StringUtils.hasText(tagListDto.getRemark()),Tag::getRemark,tagListDto.getRemark()); tagLambdaQueryWrapper.like(StringUtils.hasText(tagListDto.getName()),Tag::getName,tagListDto.getName()); Page<Tag> page = new Page <>(pageNum,pageSize); page(page,tagLambdaQueryWrapper); return ResponseResult.okResult(new PageVo (page.getRecords(),page.getTotal())); }
新增标签 接口分析 注意自动填充字段,是否创建MyMetaObjectHandler
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package com.sangeng.handle.mp;import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;import com.sangeng.utils.SecurityUtils;import org.apache.ibatis.reflection.MetaObject;import org.springframework.stereotype.Component;import java.util.Date;@Component public class MyMetaObjectHandler implements MetaObjectHandler { @Override public void insertFill (MetaObject metaObject) { Long userId = null ; try { userId = SecurityUtils.getUserId(); } catch (Exception e) { e.printStackTrace(); userId = -1L ; } this .setFieldValByName("createTime" , new Date (), metaObject); this .setFieldValByName("createBy" ,userId , metaObject); this .setFieldValByName("updateTime" , new Date (), metaObject); this .setFieldValByName("updateBy" , userId, metaObject); } @Override public void updateFill (MetaObject metaObject) { this .setFieldValByName("updateTime" , new Date (), metaObject); this .setFieldValByName(" " , SecurityUtils.getUserId(), metaObject); } }
1 2 3 4 5 6 7 @Override public ResponseResult addTag (AddTagDto addTagDto) { Tag tag = BeanCopyUtils.copyBean(addTagDto, Tag.class); save(tag); return ResponseResult.okResult(); }
1 2 3 4 5 6 @PostMapping @ApiOperation(value = "新增标签", notes = "新增标签") public ResponseResult addTag (@RequestBody AddTagDto addTagDto) { return tagService.addTag(addTagDto); }
删除标签 接口分析
代码实现 1 2 3 4 5 6 @DeleteMapping("/{id}") @ApiOperation(value = "删除标签", notes = "删除标签") public ResponseResult delete (@PathVariable List<Long> id) { tagService.removeByIds(id); return ResponseResult.okResult(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl global-config: db-config: logic-delete-field: delFlag logic-delete-value: 1 logic-not-delete-value: 0 id-type: auto
修改标签 接口分析
思路分析 注意要先根据id查询所对应的标签,进行回显,然后再根据id保存相应的数据
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @GetMapping("/{id}") @ApiOperation(value = "根据id查询标签", notes = "回显标签信息,去更新标签信息") @ApiImplicitParam(name = "id",value = "标签id") public ResponseResult getInfo (@PathVariable(value = "id") Long id) { Tag tag = tagService.getById(id); return ResponseResult.okResult(tag); } @PutMapping @ApiOperation(value = "根据id修改标签", notes = "修改标签信息") public ResponseResult edit (@RequestBody EditTagDto tagDto) { Tag tag = BeanCopyUtils.copyBean(tagDto,Tag.class); tagService.updateById(tag); return ResponseResult.okResult(); }
*发布文章 查询分类 接口分析
代码实现 1 2 3 4 5 6 7 8 9 @Override public List<CategoryVo> listAllCategory () { LambdaQueryWrapper<Category> categoryLambdaQueryWrapper = new LambdaQueryWrapper <>(); categoryLambdaQueryWrapper.eq(Category::getStatus,SystemCanstants.CATEGORY_NORMAL); List<Category> categoryList = list(categoryLambdaQueryWrapper); return BeanCopyUtils.copyBeanList(categoryList,CategoryVo.class); }
查询标签 接口分析
代码实现 1 2 3 4 5 6 7 8 9 @Override public List<TagVo> listAllTag () { LambdaQueryWrapper<Tag> tagLambdaQueryWrapper = new LambdaQueryWrapper <>(); tagLambdaQueryWrapper.select(Tag::getId,Tag::getName); List<Tag> tagList = list(tagLambdaQueryWrapper); List<TagVo> tagVos = BeanCopyUtils.copyBeanList(tagList, TagVo.class); return tagVos; }
上传图片 接口分析
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @RestController @Api(tags = "写文章-缩略图文件上传",description = "写文章-缩略图文件上传相关接口") public class UploadController { @Autowired private UpLoadService upLoadService; @PostMapping("upload") @ApiOperation(value = "上传图片",notes = "上传缩略图") @ApiImplicitParam(name = "multipartFile",value = "头像图片") public ResponseResult upload (@RequestParam("img") MultipartFile multipartFile) { return upLoadService.upLoadImg(multipartFile); } }
1 2 3 4 5 myoss: accessKey: x-qfDcVVmiT2m-efSspP5gIUJmvbMgTFBeDxnsTx secretKey: NO5vz18JlVozZRWn11fkgwn3unD0KrmRBP6frwto bucket: jiuwei-blog yuming: http:
新建文章 接口分析
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override public ResponseResult add (AddArticleDto article) { ArticleVo articleVo = BeanCopyUtils.copyBean(article, ArticleVo.class); articleVoService.save(articleVo); List<ArticleTag> articleTags = article.getTags().stream() .map(tagId -> new ArticleTag (tagId, articleVo.getId())) .collect(Collectors.toList()); articleTagService.saveBatch(articleTags); return ResponseResult.okResult(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 package com.sangeng.domain.vo;import java.util.Date;import com.baomidou.mybatisplus.annotation.FieldFill;import com.baomidou.mybatisplus.annotation.TableField;import com.baomidou.mybatisplus.annotation.TableId;import com.baomidou.mybatisplus.annotation.TableName;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;@Data @NoArgsConstructor @AllArgsConstructor @TableName("sg_article") public class ArticleVo { @TableId private Long id; private String title; private String content; private String summary; private Long categoryId; @TableField(exist = false) private String categoryName; private String thumbnail; private String isTop; private String status; private Long viewCount; private String isComment; @TableField(fill = FieldFill.INSERT) private Long createBy; @TableField(fill = FieldFill.INSERT) private Date createTime; @TableField(fill = FieldFill.INSERT_UPDATE) private Long updateBy; @TableField(fill = FieldFill.INSERT_UPDATE) private Date updateTime; private Integer delFlag; public ArticleVo (Long id, long viewCount) { this .id = id; this .viewCount = viewCount; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package com.sangeng.domain.dto;import io.swagger.annotations.ApiModel;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import java.util.List;@Data @AllArgsConstructor @NoArgsConstructor @ApiModel(value = "新增博客文章") public class AddArticleDto { private Long id; private String title; private String content; private String summary; private Long categoryId; private String thumbnail; private String isTop; private String status; private Long viewCount; private String isComment; private List<Long> tags; }
分类列表 查询分类 接口分析 代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Override public PageVo selectCategoryPage (Category category, Integer pageNum, Integer pageSize) { LambdaQueryWrapper<Category> queryWrapper = new LambdaQueryWrapper (); queryWrapper.like(StringUtils.hasText(category.getName()),Category::getName, category.getName()); queryWrapper.eq(Objects.nonNull(category.getStatus()),Category::getStatus, category.getStatus()); Page<Category> page = new Page <>(); page.setCurrent(pageNum); page.setSize(pageSize); page(page,queryWrapper); List<Category> categories = page.getRecords(); PageVo pageVo = new PageVo (); pageVo.setTotal(page.getTotal()); pageVo.setRows(categories); return pageVo; }
新增分类 接口分析
代码实现 1 2 3 4 5 6 7 @PostMapping @ApiOperation(value = "增加文章的分类", notes = "增加文章的分类") public ResponseResult add (@RequestBody AddCategoryDto categoryDto) { Category category = BeanCopyUtils.copyBean(categoryDto, Category.class); categoryService.save(category); return ResponseResult.okResult(); }
删除分类 接口分析
代码实现 1 2 3 4 5 6 @DeleteMapping(value = "/{id}") @ApiOperation(value = "删除文章的分类", notes = "删除文章的分类") public ResponseResult remove (@PathVariable(value = "id") List<Long> id) { categoryService.removeByIds(id); return ResponseResult.okResult(); }
修改分类 接口分析
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @GetMapping(value = "/{id}") @ApiOperation(value = "根据分类的id来查询分类", notes = "根据分类的id来查询分类") public ResponseResult getInfo (@PathVariable(value = "id") Long id) { Category category = categoryService.getById(id); return ResponseResult.okResult(category); } @PutMapping @ApiOperation(value = "根据分类的id来修改分类", notes = "根据分类的id来修改分类") public ResponseResult edit (@RequestBody Category category) { categoryService.updateById(category); return ResponseResult.okResult(); }
Excel表格 接口设计
接口分析 使用easyExcel实现Excel的导出操作
1 2 3 官方地址: https://github.com/alibaba/easyexcel 快速开始: https://easyexcel.opensource.alibaba.com/docs/current/quickstart/write#%E7%A4%BA%E4%BE%8B%E4%BB%A3%E7%A0%81-1
分析: 把数据库的分类数据查询出来,然后写入到Excel文件中,然后下载这个Excel文件,重点就是怎么往Excel里面写入数据,点击上面提供的快速开始的链接,点击左侧的 ‘写Excel’,就能看到实现的代码了,重点看右侧小导航栏的 ‘web中的写并且失败的时候返回json’
增加响应头,将数据变成输出流响应到浏览器,报错也响应到浏览器
代码实现 1.加入pom依赖
1 2 3 4 5 <!--easyExcel的依赖--> <dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> </dependency>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @GetMapping("/export") @ApiOperation(value = "把分类数据写入到Excel并导出", notes = "把分类数据写入到Excel并导出") public void export (HttpServletResponse response) { try { WebUtils.setDownLoadHeader("分类.xlsx" ,response); List<Category> category = categoryService.list(); List<ExcelCategoryVo> excelCategoryVos = BeanCopyUtils.copyBeanList(category, ExcelCategoryVo.class); EasyExcel.write(response.getOutputStream(), ExcelCategoryVo.class).autoCloseStream(Boolean.FALSE).sheet("文章分类" ) .doWrite(excelCategoryVos); } catch (Exception e) { ResponseResult result = ResponseResult.errorResult(AppHttpCodeEnum.SYSTEM_ERROR); WebUtils.renderString(response, JSON.toJSONString(result)); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public static void renderString (HttpServletResponse response, String string) { try { response.setStatus(200 ); response.setContentType("application/json" ); response.setCharacterEncoding("utf-8" ); response.getWriter().print(string); } catch (IOException e) { e.printStackTrace(); } } public static void setDownLoadHeader (String filename, ServletContext context, HttpServletResponse response) throws UnsupportedEncodingException { String mimeType = context.getMimeType(filename); response.setHeader("content-type" ,mimeType); String fname= URLEncoder.encode(filename,"UTF-8" ); response.setHeader("Content-disposition" ,"attachment; filename=" +fname); } public static void setDownLoadHeader (String filename, HttpServletResponse response) throws UnsupportedEncodingException { response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet" ); response.setCharacterEncoding("utf-8" ); String fname= URLEncoder.encode(filename,"UTF-8" ).replaceAll("\\+" , "%20" ); response.setHeader("Content-disposition" , "attachment;filename*=utf-8''" + fname); }
文章列表 查询文章 接口分析
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Override public PageVo selectArticlePage (Article article, Integer pageNum, Integer pageSize) { LambdaQueryWrapper<Article> queryWrapper = new LambdaQueryWrapper (); queryWrapper.like(StringUtils.hasText(article.getTitle()),Article::getTitle, article.getTitle()); queryWrapper.like(StringUtils.hasText(article.getSummary()),Article::getSummary, article.getSummary()); Page<Article> page = new Page <>(); page.setCurrent(pageNum); page.setSize(pageSize); page(page,queryWrapper); List<Article> articles = page.getRecords(); PageVo pageVo = new PageVo (); pageVo.setTotal(page.getTotal()); pageVo.setRows(articles); return pageVo; }
修改文章 接口设计
思路分析 首先根据文章id查询文件信息,再根据文章id去标签-文章的表去查询文章id所对应的tagid 然后将tagid赋值给文章实体类的tagid集合
然后根据文章id,去修改文章的分类信息,然后删除旧的文章-标签对应关系,增加新的标签-文章对应关系
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @GetMapping(value = "/{id}") @ApiOperation(value = "先查询根据文章id查询对应的文章", notes = "先查询根据文章id查询对应的文章") public ResponseResult getInfo (@PathVariable(value = "id") Long id) { ArticleByIdVo article = articleService.getInfo(id); return ResponseResult.okResult(article); } @PutMapping @ApiOperation(value = "修改文章", notes = "修改文章") public ResponseResult edit (@RequestBody ArticleDto article) { articleService.edit(article); return ResponseResult.okResult(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @Override public ArticleByIdVo getInfo (Long id) { Article article = getById(id); LambdaQueryWrapper<ArticleTag> articleTagLambdaQueryWrapper = new LambdaQueryWrapper <>(); articleTagLambdaQueryWrapper.eq(ArticleTag::getArticleId,article.getId()); List<ArticleTag> articleTags = articleTagService.list(articleTagLambdaQueryWrapper); List<Long> tags = articleTags.stream().map(articleTag -> articleTag.getTagId()).collect(Collectors.toList()); ArticleByIdVo articleVo = BeanCopyUtils.copyBean(article,ArticleByIdVo.class); articleVo.setTags(tags); return articleVo; } @Override public void edit (ArticleDto articleDto) { Article article = BeanCopyUtils.copyBean(articleDto, Article.class); updateById(article); LambdaQueryWrapper<ArticleTag> articleTagLambdaQueryWrapper = new LambdaQueryWrapper <>(); articleTagLambdaQueryWrapper.eq(ArticleTag::getArticleId,article.getId()); articleTagService.remove(articleTagLambdaQueryWrapper); List<ArticleTag> articleTags = articleDto.getTags().stream() .map(tagId -> new ArticleTag (articleDto.getId(), tagId)) .collect(Collectors.toList()); articleTagService.saveBatch(articleTags); }
删除文章 接口分析
代码实现 1 2 3 4 5 6 7 @DeleteMapping("/{id}") @ApiOperation(value = "删除文章", notes = "删除文章") public ResponseResult delete (@PathVariable List<Long> id) { articleService.removeByIds(id); return ResponseResult.okResult(); }
菜单列表 查询菜单 接口分析
响应格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 { "code" :200 , "data" :[ { "component" :"组件路径" , "icon" :"build" , "id" :"2023" , "isFrame" :1 , "menuName" :"菜单名称" , "menuType" :"C" , "orderNum" :0 , "parentId" :"0" , "path" :"write" , "perms" :"权限字符串" , "remark" :"备注信息" , "status" :"0" , "visible" :"0" }, { "icon" :"system" , "id" :"1" , "isFrame" :1 , "menuName" :"菜单名称" , "menuType" :"M" , "orderNum" :1 , "parentId" :"0" , "path" :"system" , "perms" :"权限字符串" , "remark" :"备注信息" , "status" :"0" , "visible" :"0" } ], "msg" :"操作成功" }
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override public List<Menu> selectMenuList (Menu menu) { LambdaQueryWrapper<Menu> queryWrapper = new LambdaQueryWrapper <>(); queryWrapper.like(StringUtils.hasText(menu.getMenuName()),Menu::getMenuName,menu.getMenuName()); queryWrapper.eq(StringUtils.hasText(menu.getStatus()),Menu::getStatus,menu.getStatus()); queryWrapper.orderByAsc(Menu::getParentId,Menu::getOrderNum); List<Menu> menus = list(queryWrapper);; return menus; }
新增菜单 接口分析
代码实现 1 2 3 4 5 6 @PostMapping @ApiOperation(value = "新增菜单列表", notes = "新增菜单列表") public ResponseResult add (@RequestBody Menu menu) { menuService.save(menu); return ResponseResult.okResult(); }
修改菜单 接口分析
思路分析 先根据菜单id查询出菜单信息,回显数据
在根据id更新所修改的信息,修改的时候判断所修改的菜单是否是父菜单,不能把父菜单设置为当前菜单
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @GetMapping(value = "/{menuId}") @ApiOperation(value = "查询菜单信息", notes = "查询菜单信息") public ResponseResult getInfo (@PathVariable Long menuId) { return ResponseResult.okResult(menuService.getById(menuId)); } @PutMapping public ResponseResult edit (@RequestBody Menu menu) { if (menu.getId().equals(menu.getParentId())) { return ResponseResult.errorResult(500 ,"修改菜单'" + menu.getMenuName() + "'失败,上级菜单不能选择自己" ); } menuService.updateById(menu); return ResponseResult.okResult(); }
删除菜单 接口分析
思路分析 判断是否有子目录,就是看其他的parentid是否有它
代码实现 1 2 3 4 5 6 7 8 @Override public boolean hasChild (Long menuId) { LambdaQueryWrapper<Menu> menulambdaQueryWrapper = new LambdaQueryWrapper <>(); menulambdaQueryWrapper.eq(Menu::getParentId,menuId); return count(menulambdaQueryWrapper)>0 ; }
角色列表 查询角色 接口设计
响应
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 { "code" : 200 , "data" : { "rows" : [ { "id" : "12" , "roleKey" : "link" , "roleName" : "角色名称" , "roleSort" : "1" , "status" : "0" } ] , "total" : "1" } , "msg" : "操作成功" }
思路分析 根据条件模糊查询,,将分页信息封装到vo返回给前端
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Override public ResponseResult selectRolePage (Role role, Integer pageNum, Integer pageSize) { LambdaQueryWrapper<Role> lambdaQueryWrapper = new LambdaQueryWrapper <>(); lambdaQueryWrapper.like(StringUtils.hasText(role.getRoleName()),Role::getRoleName,role.getRoleName()); lambdaQueryWrapper.eq(StringUtils.hasText(role.getStatus()),Role::getStatus,role.getStatus()); lambdaQueryWrapper.orderByAsc(Role::getRoleSort); Page<Role> page = new Page <>(); page.setCurrent(pageNum); page.setSize(pageSize); page(page,lambdaQueryWrapper); List<Role> roles = page.getRecords(); PageVo pageVo = new PageVo (); pageVo.setTotal(page.getTotal()); pageVo.setRows(roles); return ResponseResult.okResult(pageVo); }
修改状态 接口设计
思路分析 设置Role所要更新的信息,然后调用mp的更新方法去更新
代码实现 1 2 3 4 5 6 7 8 @PutMapping("/changeStatus") @ApiOperation(value = "修改角色的状态", notes = "修改角色的状态") public ResponseResult changeStatus (@RequestBody ChangeRoleStatusDto roleStatusDto) { Role role = new Role (); role.setId(roleStatusDto.getRoleId()); role.setStatus(roleStatusDto.getStatus()); return ResponseResult.okResult(roleService.updateById(role)); }
新增角色 接口设计
响应
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 { "code" : 200 , "data" : [ { "children" : [ ] , "id" : "2023" , "label" : "写博文" , "parentId" : "0" } , { "children" : [ { "children" : [ { "children" : [ ] , "id" : "1001" , "label" : "用户查询" , "parentId" : "100" } , { "children" : [ ] , "id" : "1007" , "label" : "重置密码" , "parentId" : "100" } ] , "id" : "100" , "label" : "用户管理" , "parentId" : "1" } , { "children" : [ { "children" : [ ] , "id" : "2024" , "label" : "友链新增" , "parentId" : "2022" } , { "children" : [ ] , "id" : "2025" , "label" : "友链修改" , "parentId" : "2022" } ] , "id" : "2022" , "label" : "友链管理" , "parentId" : "2017" } ] , "id" : "2017" , "label" : "内容管理" , "parentId" : "0" } ] , "msg" : "操作成功" }
思路分析 首先打开新增窗口,需要查询出菜单树 可以先找出第一层菜单,然后根据i第一层的菜单id,找出其他菜单父类id为它的菜单,然后将这些菜单设置为第一层菜单的children
然后新增所填写的角色信息
并且需要将角色和菜单的对应关系加到角色-菜单关联关系表
代码实现 ①
1 2 3 4 5 6 7 8 @GetMapping("/treeselect") @ApiOperation(value = "新增角色--获取菜单下拉树列表", notes = "新增角色--获取菜单下拉树列表") public ResponseResult treeselect () { List<Menu> menus = menuService.selectMenuList(new Menu ()); List<MenuTreeVo> options = SystemConverter.buildMenuSelectTree(menus); return ResponseResult.okResult(options); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package com.sangeng.utils;import com.sangeng.domain.entity.Menu;import com.sangeng.domain.vo.MenuTreeVo;import java.util.List;import java.util.stream.Collectors;public class SystemConverter { public SystemConverter () { } public static List<MenuTreeVo> buildMenuSelectTree (List<Menu> menus) { List<MenuTreeVo> menuTreeVos = menus.stream() .map(menu -> new MenuTreeVo (menu.getId(), menu.getMenuName(), menu.getParentId(), null )) .collect(Collectors.toList()); List<MenuTreeVo> menuTree = menuTreeVos.stream().filter(menuTreeVo -> menuTreeVo.getParentId().equals(0L )) .map(menuTreeVo -> menuTreeVo.setChildren(getChildren(menuTreeVo, menuTreeVos))) .collect(Collectors.toList()); return menuTree; } private static List<MenuTreeVo> getChildren (MenuTreeVo menuTreeVo,List<MenuTreeVo> menuTreeVos) { List<MenuTreeVo> childrenTree = menuTreeVos.stream().filter(m -> m.getParentId().equals(menuTreeVo.getId())) .map(m -> m.setChildren(getChildren(m, menuTreeVos))).collect(Collectors.toList()); return childrenTree; } }
②
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Override public void insertRole (Role role) { save(role); if (role.getMenuIds()!=null &&role.getMenuIds().length>0 ) { insertRoleMenu(role); } } private void insertRoleMenu (Role role) { List<RoleMenu> roleMenu = Arrays.stream(role.getMenuIds()).map(menuId -> new RoleMenu (menuId, role.getId())) .collect(Collectors.toList()); roleMenuService.saveBatch(roleMenu); }
1 2 3 4 5 6 @PostMapping @ApiOperation(value = "新增角色", notes = "新增角色") public ResponseResult add ( @RequestBody Role role) { roleService.insertRole(role); return ResponseResult.okResult(); }
修改角色 接口设计 ①
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 { "code" : 200 , "data" : { "id" : "11" , "remark" : "备注信息" , "roleKey" : "aggag" , "roleName" : "角色名称" , "roleSort" : "5" , "status" : "0" } , "msg" : "操作成功" } { "code" : 200 , "data" : { "id" : "11" , "remark" : "备注信息" , "roleKey" : "aggag" , "roleName" : "角色名称" , "roleSort" : "5" , "status" : "0" } , "msg" : "操作成功" }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 { "code" :200 , "data" :{ "menus" :[ { "children" :[], "id" :"2023" , "label" :"写博文" , "parentId" :"0" }, { "children" :[ { "children" :[ { "children" :[], "id" :"1001" , "label" :"用户查询" , "parentId" :"100" }, { "children" :[], "id" :"1002" , "label" :"用户新增" , "parentId" :"100" } ], "id" :"100" , "label" :"用户管理" , "parentId" :"1" }, { "children" :[ { "children" :[], "id" :"1008" , "label" :"角色查询" , "parentId" :"101" } ], "id" :"101" , "label" :"角色管理" , "parentId" :"1" } ], "id" :"1" , "label" :"系统管理" , "parentId" :"0" }, { "children" :[ { "children" :[], "id" :"2019" , "label" :"文章管理" , "parentId" :"2017" }, { "children" :[ { "children" :[], "id" :"2028" , "label" :"导出分类" , "parentId" :"2018" } ], "id" :"2018" , "label" :"分类管理" , "parentId" :"2017" }, { "children" :[ { "children" :[], "id" :"2024" , "label" :"友链新增" , "parentId" :"2022" }, { "children" :[], "id" :"2025" , "label" :"友链修改" , "parentId" :"2022" } ], "id" :"2022" , "label" :"友链管理" , "parentId" :"2017" }, { "children" :[], "id" :"2021" , "label" :"标签管理" , "parentId" :"2017" } ], "id" :"2017" , "label" :"内容管理" , "parentId" :"0" } ], "checkedKeys" :[ "1001" ] }, "msg" :"操作成功" }
思路分析 首先根据角色id查询角色信息回显到修改窗口
然后回显菜单树,和这个角色之前选的菜单的id(根据角色id查找对应的菜单id集合)
最后把修改的角色信息保存到数据库中,把菜单角色关联表中的这个角色id之前信息删除,在重新添加关联信息
代码实现 1 2 3 4 5 6 7 @GetMapping("/{id}") @ApiOperation(value = "获取修改id角色信息", notes = "获取修改id角色信息") @ApiImplicitParam(name = "id",value = "角色id") public ResponseResult selectById (@PathVariable Long id) { Role role = roleService.getById(id); return ResponseResult.okResult(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 @GetMapping(value = "/roleMenuTreeselect/{roleId}") @ApiOperation(value = "修改角色-根据角色id查询对应角色菜单列表树-", notes = "修改角色-根据角色id查询对应角色菜单列表树-") public ResponseResult roleMenuTreeSelect (@PathVariable("roleId") Long roleId) { List<Menu> menus = menuService.selectMenuList(new Menu ()); List<MenuTreeVo> menuTreeVos = SystemConverter.buildMenuSelectTree(menus); List<Long> checkedKeys = menuService.selectMenuListByRoleId(roleId); RoleMenuTreeSelectVo vo = new RoleMenuTreeSelectVo (checkedKeys,menuTreeVos); return ResponseResult.okResult(vo); }
1 2 3 4 5 6 7 <!--修改角色-根据角色id查询对应角色的菜单列表树--> <select id="selectMenuListByRoleId" resultType="java.lang.Long" > select * from sys_menu m left join sys_role_menu rm on m.id = rm.menu_id where rm.role_id = #{roleId} order by m.parent_id , m.order_num </select>
1 2 3 4 5 6 7 8 9 10 @Override public void updateRole (Role role) { updateById(role); roleMenuService.deleteRoleMenuByRoleId(role.getId()); insertRoleMenu(role); }
1 2 3 4 5 6 7 @Override public void deleteRoleMenuByRoleId (Long id) { LambdaQueryWrapper<RoleMenu> queryWrapper = new LambdaQueryWrapper <>(); queryWrapper.eq(RoleMenu::getRoleId,id); remove(queryWrapper); }
删除角色 接口设计
代码实现 1 2 3 4 5 6 7 @DeleteMapping("/{id}") @ApiOperation(value = "删除角色", notes = "删除角色") @ApiImplicitParam(name = "id",value = "角色id") public ResponseResult remove (@PathVariable(name = "id") Long id) { roleService.removeById(id); return ResponseResult.okResult(); }
用户列表 查询用户 接口分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 { "code" : 200 , "data" : { "rows" : [ { "avatar" : "头像url" , "createTime" : "2023-08-05 17:01:56" , "email" : "23412332@qq.com" , "id" : "1" , "nickName" : "昵称" , "phonenumber" : "18888888888" , "sex" : "1" , "status" : "0" , "updateBy" : "1" , "updateTime" : "2023-08-10 21:36:22" , "userName" : "sg" } ] , "total" : "1" } , "msg" : "操作成功" }
代码实现 //——————————–查询用户列表————————————- queryWrapper = new LambdaQueryWrapper();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 queryWrapper.like(StringUtils.hasText(user.getUserName()), User::getUserName, user.getUserName()); queryWrapper.eq(StringUtils.hasText(user.getStatus()), User::getStatus, user.getStatus()); queryWrapper.eq(StringUtils.hasText(user.getPhonenumber()), User::getPhonenumber, user.getPhonenumber()); Page<User> page = new Page <>(); page.setCurrent(pageNum); page.setSize(pageSize); page(page, queryWrapper); List<User> users = page.getRecords(); List<UserVo> userVoList = users.stream() .map(u -> BeanCopyUtils.copyBean(u, UserVo.class)) .collect(Collectors.toList()); PageVo pageVo = new PageVo (); pageVo.setTotal(page.getTotal()); pageVo.setRows(userVoList); return ResponseResult.okResult(pageVo); }
新增用户 思路分析 首先查出所有角色,然后增加用户,把角色和用户对应关系也需要保存到关联表中
接口分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 { "code" : 200 , "data" : [ { "createBy" : "0" , "createTime" : "2023-08-12 18:46:19" , "delFlag" : "0" , "id" : "1" , "remark" : "超级管理员" , "roleKey" : "admin" , "roleName" : "超级管理员" , "roleSort" : "1" , "status" : "0" , "updateBy" : "0" } , { "createBy" : "0" , "createTime" : "2023-08-12 18:46:19" , "delFlag" : "0" , "id" : "2" , "remark" : "普通角色" , "roleKey" : "common" , "roleName" : "普通角色" , "roleSort" : "2" , "status" : "0" , "updateBy" : "0" , "updateTime" : "2023-08-13 06:32:58" } ] , "msg" : "操作成功" }
代码实现 1 2 3 4 5 6 7 8 @GetMapping("/listAllRole") public ResponseResult listAllRole () { List<Role> roles = roleService.selectRoleAll(); return ResponseResult.okResult(roles); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 @Autowired private UserRoleService userRoleService; @Override public boolean checkUserNameUnique (String userName) { return count(Wrappers.<User>lambdaQuery().eq(User::getUserName,userName))==0 ; } @Override public boolean checkPhoneUnique (User user) { return count(Wrappers.<User>lambdaQuery().eq(User::getPhonenumber,user.getPhonenumber()))==0 ; } @Override public boolean checkEmailUnique (User user) { return count(Wrappers.<User>lambdaQuery().eq(User::getEmail,user.getEmail()))==0 ; } @Override @Transactional public ResponseResult addUser (User user) { user.setPassword(passwordEncoder.encode(user.getPassword())); save(user); if (user.getRoleIds()!=null &&user.getRoleIds().length>0 ){ insertUserRole(user); } return ResponseResult.okResult(); } private void insertUserRole (User user) { List<UserRole> sysUserRoles = Arrays.stream(user.getRoleIds()) .map(roleId -> new UserRole (user.getId(), roleId)).collect(Collectors.toList()); userRoleService.saveBatch(sysUserRoles); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @PostMapping @ApiOperation(value = "新增用户",notes = "新增用户") public ResponseResult add (@RequestBody User user) { if (!StringUtils.hasText(user.getUserName())){ throw new SystemException (AppHttpCodeEnum.REQUIRE_USERNAME); } if (!userService.checkUserNameUnique(user.getUserName())){ throw new SystemException (AppHttpCodeEnum.USERNAME_EXIST); } if (!userService.checkPhoneUnique(user)){ throw new SystemException (AppHttpCodeEnum.PHONENUMBER_EXIST); } if (!userService.checkEmailUnique(user)){ throw new SystemException (AppHttpCodeEnum.EMAIL_EXIST); } return userService.addUser(user); }
删除用户 接口分析
代码实现 1 2 3 4 5 6 7 8 9 @DeleteMapping("/{userIds}") @ApiOperation(value = "删除用户",notes = "删除用户") public ResponseResult remove (@PathVariable List<Long> userIds) { if (userIds.contains(SecurityUtils.getUserId())){ return ResponseResult.errorResult(500 ,"不能删除当前你正在使用的用户" ); } userService.removeByIds(userIds); return ResponseResult.okResult(); }
修改用户 思路分析 先查找出该用户所有的角色信息,然后删除该用户的角色用户的关联关系,
然后插入新的关联信息,最后插入用户表信息
接口分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 { "code" : 200 , "data" : { "roleIds" : [ "11" ] , "roles" : [ { "createBy" : "0" , "createTime" : "2023-08-10 18:46:19" , "delFlag" : "0" , "id" : "1" , "remark" : "超级管理员" , "roleKey" : "admin" , "roleName" : "超级管理员" , "roleSort" : "1" , "status" : "0" , "updateBy" : "0" } , { "createBy" : "0" , "createTime" : "2023-08-10 18:46:19" , "delFlag" : "0" , "id" : "2" , "remark" : "普通角色" , "roleKey" : "common" , "roleName" : "普通角色" , "roleSort" : "2" , "status" : "0" , "updateBy" : "0" , "updateTime" : "2023-08-11 06:32:58" } ] , "user" : { "email" : "weq@2132.com" , "id" : "用户id" , "nickName" : "昵称" , "sex" : "0" , "status" : "0" , "userName" : "用户名" } } , "msg" : "操作成功" }
代码实现 1 2 3 4 5 6 7 <!--修改用户-①根据id查询用户角色信息--> <select id="selectRoleIdByUserId" resultType="java.lang.Long" > select r.id from sys_role r left join sys_user_role ur on ur.role_id = r.id where ur.user_id = #{userId} </select>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 private void insertUserRole (User user) { List<UserRole> sysUserRoles = Arrays.stream(user.getRoleIds()) .map(roleId -> new UserRole (user.getId(), roleId)).collect(Collectors.toList()); userRoleService.saveBatch(sysUserRoles); } @Override @Transactional public void updateUser (User user) { LambdaQueryWrapper<UserRole> userRoleUpdateWrapper = new LambdaQueryWrapper <>(); userRoleUpdateWrapper.eq(UserRole::getUserId,user.getId()); userRoleService.remove(userRoleUpdateWrapper); insertUserRole(user); updateById(user); }
友链列表 查询友链 接口分析
代码实现 1 2 PageVo selectLinkPage (Link link, Integer pageNum, Integer pageSize) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Override public PageVo selectLinkPage (Link link, Integer pageNum, Integer pageSize) { LambdaQueryWrapper<Link> queryWrapper = new LambdaQueryWrapper (); queryWrapper.like(StringUtils.hasText(link.getName()),Link::getName, link.getName()); queryWrapper.eq(Objects.nonNull(link.getStatus()),Link::getStatus, link.getStatus()); Page<Link> page = new Page <>(); page.setCurrent(pageNum); page.setSize(pageSize); page(page,queryWrapper); List<Link> categories = page.getRecords(); PageVo pageVo = new PageVo (); pageVo.setTotal(page.getTotal()); pageVo.setRows(categories); return pageVo; }
新增友链 接口分析
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 package com.sangeng.domain.entity;import java.util.Date;import java.io.Serializable;import com.baomidou.mybatisplus.annotation.FieldFill;import com.baomidou.mybatisplus.annotation.TableField;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import com.baomidou.mybatisplus.annotation.TableId;import com.baomidou.mybatisplus.annotation.TableName;@Data @AllArgsConstructor @NoArgsConstructor @TableName("sg_link") public class Link { @TableId private Long id; private String name; private String logo; private String description; private String address; private String status; @TableField(fill = FieldFill.INSERT) private Long createBy; @TableField(fill = FieldFill.INSERT) private Date createTime; @TableField(fill = FieldFill.INSERT_UPDATE) private Long updateBy; @TableField(fill = FieldFill.INSERT_UPDATE) private Date updateTime; private Integer delFlag; }
修改友链 思路分析 先根据id查询友链,然后修改友链的状态,最后修改友链
接口分析
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @GetMapping(value = "/{id}") public ResponseResult getInfo (@PathVariable(value = "id") Long id) { Link link = linkService.getById(id); return ResponseResult.okResult(link); } @PutMapping("/changeLinkStatus") public ResponseResult changeLinkStatus (@RequestBody Link link) { linkService.updateById(link); return ResponseResult.okResult(); } @PutMapping public ResponseResult edit (@RequestBody Link link) { linkService.updateById(link); return ResponseResult.okResult(); }
删除友链 接口分析
代码实现 1 2 3 4 5 6 @DeleteMapping("/{id}") @ApiOperation(value = "删除友链", notes = "删除友链") public ResponseResult delete (@PathVariable Long id) { linkService.removeById(id); return ResponseResult.okResult(); }
Leetcode 2024/4/2 前序遍历,首先判断是不是左叶子(左节点不为null,左节点的左孩和右孩子为null)。然后进行递归遍历左右孩子,最后返回sum
[] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { int sum = 0 ; public int sumOfLeftLeaves (TreeNode root) { if (root == null ) return 0 ; if (root.left!=null && root.left.left==null && root.left.right==null ) { sum+=root.left.val; } sumOfLeftLeaves(root.left); sumOfLeftLeaves(root.right); return sum; } }
BFS 广度优先搜索。从右往左对每一层进行遍历,最后一层的最后一个节点就是左下角的值
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { public int findBottomLeftValue (TreeNode root) { Deque<TreeNode> queue = new LinkedList <>(); if (root==null ) return 0 ; queue.offerLast(root); int res = 0 ; while (!queue.isEmpty()) { TreeNode node = queue.pollFirst(); res = node.val; if (node.right!=null ) queue.addLast(node.right); if (node.left!=null ) queue.addLast(node.left); } return res; } }
让root1作为合并后的树,然后让root2上的值加到root1
深度优先遍历
结束条件:root1==null 直接返回root2 相反 root2==null 直接返回root1
过程:roo1+=root2,然后遍历左子树和右子树
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution { public TreeNode mergeTrees (TreeNode root1, TreeNode root2) { if (root1==null ) return root2; if (root2==null ) return root1; root1.val = root1.val+root2.val; root1.left = mergeTrees(root1.left,root2.left); root1.right = mergeTrees(root1.right,root2.right); return root1; } }
思路:DFS遍历
递归终止条件:左右节点为null,计数器等于targetSum(或者每次用targetSum都减节点数最后为0 )返回true ,返回false 左右节点都为null
单层递归逻辑
遍历左子树 count+val 如果到最后一个节点 然后执行 count-val回退到上一个根节点
右子树一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public boolean hasPathSum (TreeNode root, int targetSum) { if (root==null ) return false ; int count = 0 ; targetSum = targetSum - root.val; boolean flag = dfs(root,targetSum); return flag; } boolean dfs (TreeNode root, int count) { if (root.left==null && root.right ==null && count==0 ) return true ; if (root.left==null && root.right == null ) return false ; if (root.left!=null ) { count = count-root.left.val; if (dfs(root.left,count)) return true ; count = count + root.left.val; } if (root.right!=null ) { count = count - root.right.val; if (dfs(root.right,count)) return true ; count = count + root.right.val; } return false ; } }
1 2 GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP,ALTER,INDEX on *.* TO 'root'@'8.130.97.224' IDENTIFIED BY 123456; flush privileges;
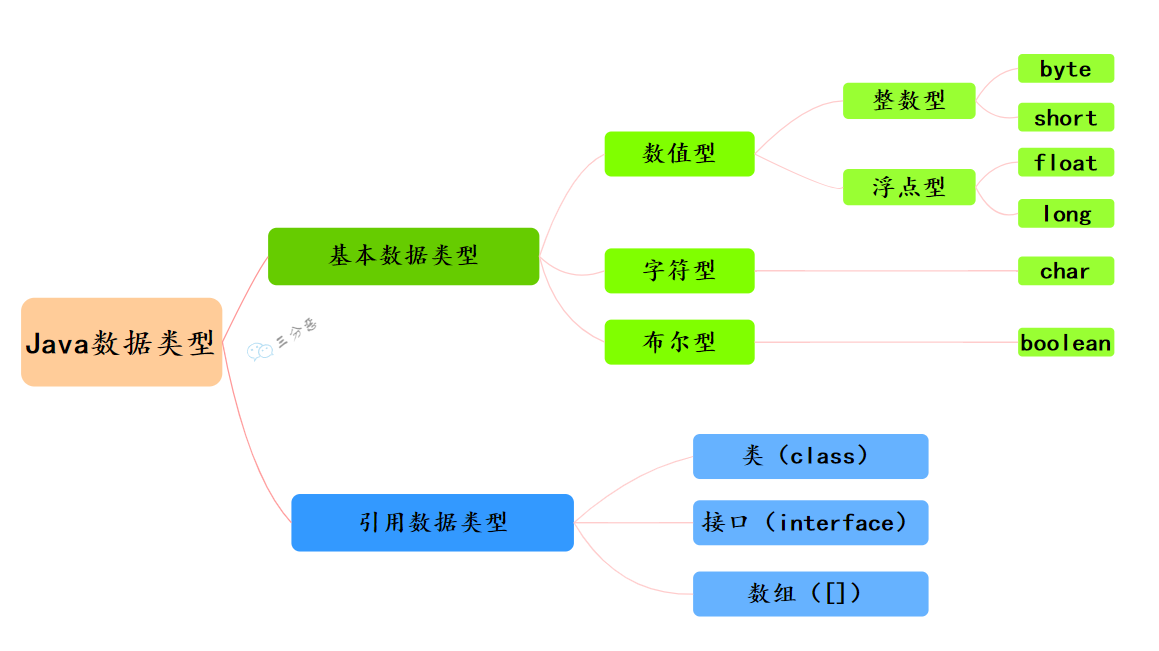 Java数据类型
Java数据类型












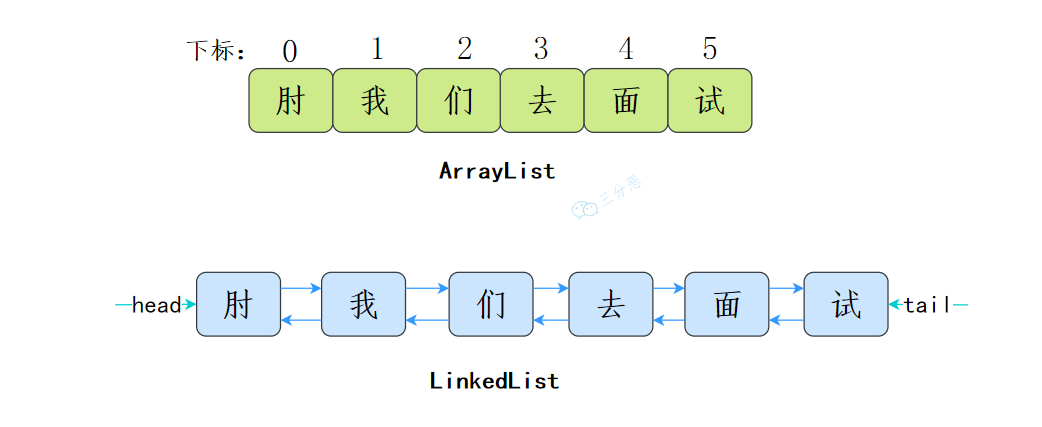 ArrayList和LinkedList的数据结构
ArrayList和LinkedList的数据结构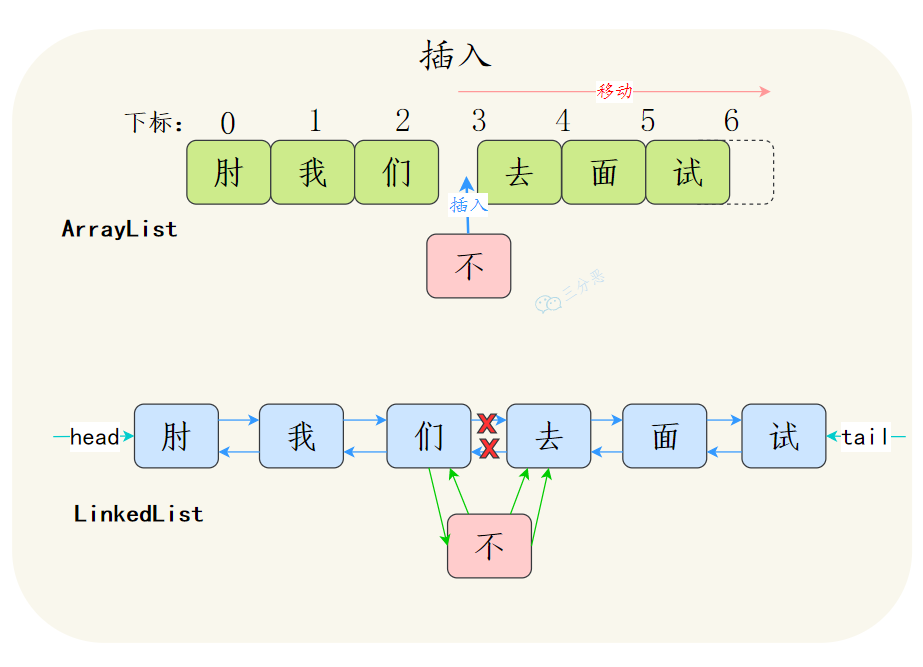 ArrayList和LinkedList中间插入
ArrayList和LinkedList中间插入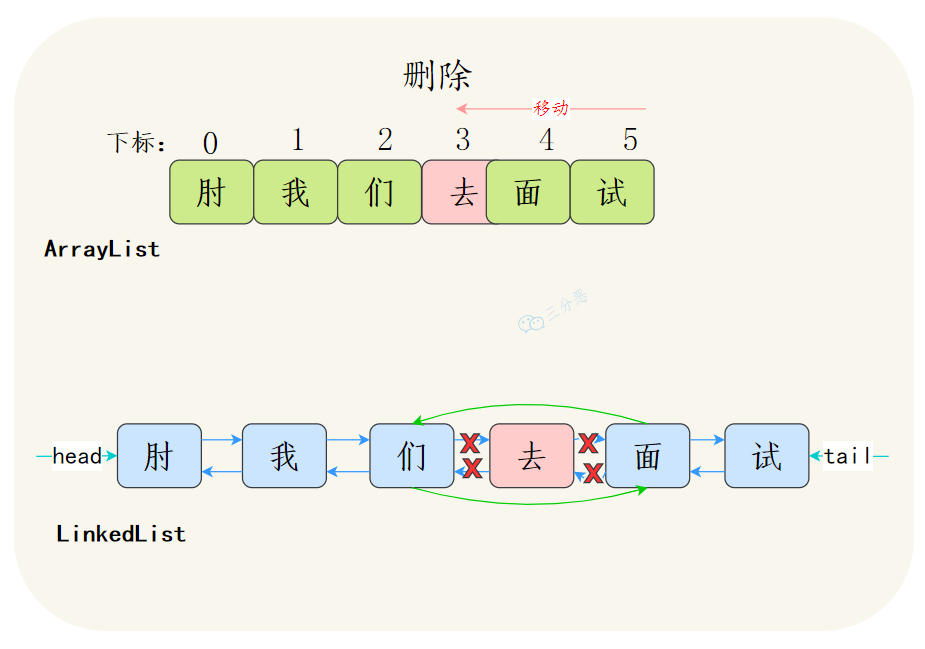 ArrayList和LinkedList中间删除
ArrayList和LinkedList中间删除













































 DROP语句
DROP语句
 UPDATE语句
UPDATE语句 DETELE语句
DETELE语句





























 1页可以有16行,也就是16k ,一页也就1024个字节。n代表当前节点存在key的数量,n+1代表指针,key+指针
1页可以有16行,也就是16k ,一页也就1024个字节。n代表当前节点存在key的数量,n+1代表指针,key+指针




















 页合并:如果一个页中删除的数据大于这个页的50%,就可以找前后两个看看是否可以合并
页合并:如果一个页中删除的数据大于这个页的50%,就可以找前后两个看看是否可以合并