LeetCode 找出数组中重复的数字。
示例 1:
1 2 3 输入: [2, 3, 1, 0, 2, 5, 3] 输出:2 或 3
限制:
解答:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution { public int findRepeatNumber (int [] nums) { int i=0 ; while (i<nums.length){ if (nums[i]==i){ i++; continue ; } if (nums[i]==nums[nums[i]]) return nums[i]; int temp = nums[i]; nums[i] = nums[temp]; nums[temp] = temp; } return -1 ; } }
请实现一个函数,把字符串 s 中的每个空格替换成”%20”。
示例 1:
1 2 输入:s = "We are happy." 输出:"We%20are%20happy."
限制:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { /* 1.遍历列表 s 中的每个字符 c : 当 c 为空格时:向 res 后添加字符串 "%20" ; 当 c 不为空格时:向 res 后添加字符 c ; 将列表 res 转化为字符串并返回,时间复杂度O(n),空间复杂度O(n) 2.或者直接使用replaceAll(原字符,新字符); */ public String replaceSpace(String s) { StringBuilder sb = new StringBuilder(); for (Character c: s.toCharArray() ) { if (c == ' ') { sb.append('%').append('2').append('0'); } else { sb.append(c); } } return sb.toString(); // return s.replaceAll(" ","%20"); } }
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
示例 1:
1 2 输入:head = [1,3,2] 输出:[2,3,1]
限制:
704 二分查找 前提是数组为有序数组 ,同时题目还强调数组中无重复元素 ,因为一旦有重复元素,使用二分查找法返回的元素下标可能不是唯一的,这些都是使用二分法的前提条件
区间的定义这就决定了二分法的代码应该如何写,因为定义target在[left, right]区间,所以有如下两点:
while (left <= right) 要使用 <= ,因为left == right是有意义的,所以使用 <=
if (nums[middle] > target) right 要赋值为 middle - 1,因为当前这个nums[middle]一定不是target(已经确定了这个middle不是target),那么接下来要查找的左区间(就不用判断这个值了,判断前一个值就ok)结束下标位置就是 middle - 1
定义 target 是在一个在左闭右开的区间里,也就是[left, right) ,那么二分法的边界处理方式则截然不同。
有如下两点:
while (left < right),这里使用 < ,因为left == right在区间[left, right)是没有意义的
if (nums[middle] > target) right 更新为 middle,因为当前nums[middle]不等于target,去左区间继续寻找,而寻找区间是左闭右开区间,所以right更新为middle,即:下一个查询区间不会去比较nums[middle]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public int search (int [] nums, int target) { if (target<nums[0 ] || target > nums[nums.length-1 ]){ return -1 ; } int left = 0 ; int right = nums.length-1 ; while (left<=right) { int middle = right+(left-right)/2 ; if (nums[middle] > target) { right = middle-1 ; } else if (nums[middle] < target) { left = middle + 1 ; } else { return middle; } } return -1 ; } }
27 移除元素 暴力破解
https://code-thinking.cdn.bcebos.com/gifs/27.%E7%A7%BB%E9%99%A4%E5%85%83%E7%B4%A0-%E6%9A%B4%E5%8A%9B%E8%A7%A3%E6%B3%95.gif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public int removeElement (int [] nums, int val) { int size = nums.length; for (int i=0 ;i<size;i++){ if (nums[i]==val){ for (int j=i+1 ;j<size;j++){ nums[j-1 ] = nums[j]; } i--; size--; } } return size; } }
双指针法
https://code-thinking.cdn.bcebos.com/gifs/27.%E7%A7%BB%E9%99%A4%E5%85%83%E7%B4%A0-%E5%8F%8C%E6%8C%87%E9%92%88%E6%B3%95.gif
时间复杂度 O(n)
空间复杂度O(1)
快指针:寻找新数组的元素 ,新数组就是不含有目标元素的数组
慢指针:指向更新 新数组下标的位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public int removeElement (int [] nums, int val) { int size = nums.length; int slow=0 ; for (int fast=0 ;fast<size;fast++){ if (nums[fast]!=val){ nums[slow] = nums[fast]; slow++; } } return slow; } }
977有序数组的平方 双指针法
数组其实是有序的, 只不过负数平方之后可能成为最大数了。
那么数组平方的最大值就在数组的两端,不是最左边就是最右边,不可能是中间。
此时可以考虑双指针法了,i指向起始位置,j指向终止位置。
定义一个新数组result,和A数组一样的大小,让k指向result数组终止位置。
如果A[i] * A[i] < A[j] * A[j] 那么result[k--] = A[j] * A[j]; 。
如果A[i] * A[i] >= A[j] * A[j] 那么result[k--] = A[i] * A[i]; 。
如动画所示:
https://code-thinking.cdn.bcebos.com/gifs/977.%E6%9C%89%E5%BA%8F%E6%95%B0%E7%BB%84%E7%9A%84%E5%B9%B3%E6%96%B9.gif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public int [] sortedSquares(int [] nums) { int size = nums.length-1 ; int left=0 ; int right=size; int [] target = new int [size+1 ]; int index=target.length-1 ; while (left<=right) { if (nums[left]*nums[left]>nums[right]*nums[right]) { target[index--] = nums[left]*nums[left]; left++; } else { target[index--] = nums[right]*nums[right]; right--; } } return target; } }
暴力破解
时间复杂度 O(n+nlog(n))
空间复杂度O(1)
1 2 3 4 5 6 7 8 9 10 class Solution { public int [] sortedSquares(int [] nums) { for (int i=0 ;i<nums.length;i++){ nums[i] = nums[i]*nums[i]; } Arrays.sort(nums); return nums; } }
209长度最小的子数组 滑动窗口
首先要思考 如果用一个for循环,那么应该表示 滑动窗口的起始位置,还是终止位置。
如果只用一个for循环来表示 滑动窗口的起始位置,那么如何遍历剩下的终止位置?
此时难免再次陷入 暴力解法的怪圈。
所以 只用一个for循环,那么这个循环的索引,一定是表示 滑动窗口的终止位置。
那么问题来了, 滑动窗口的起始位置如何移动呢?
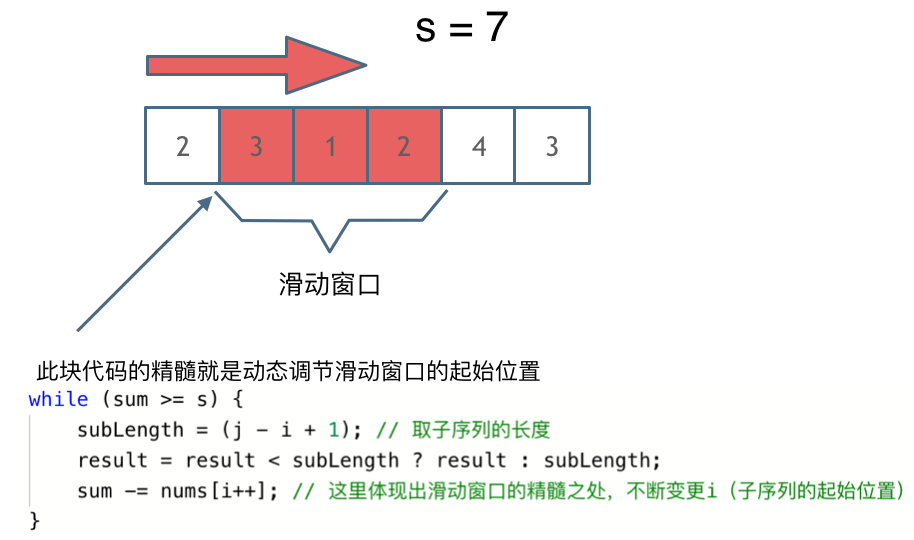
这里还是以题目中的示例来举例,s=7, 数组是 2,3,1,2,4,3,来看一下查找的过程:
最后找到 4,3 是最短距离。
其实从动画中可以发现滑动窗口也可以理解为双指针法的一种!只不过这种解法更像是一个窗口的移动,所以叫做滑动窗口更适合一些。
在本题中实现滑动窗口,主要确定如下三点:
窗口内是什么?
如何移动窗口的起始位置?
如何移动窗口的结束位置?
窗口就是 满足其和 ≥ s 的长度最小的 连续 子数组。
窗口的起始位置如何移动:如果当前窗口的值大于s了,窗口就要向前移动了(也就是该缩小了)。
窗口的结束位置如何移动:窗口的结束位置就是遍历数组的指针,也就是for循环里的索引。
解题的关键在于 窗口的起始位置如何移动,如图所示:
可以发现滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)暴力解法降为O(n)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public int minSubArrayLen (int target, int [] nums) { int result=Integer.MAX_VALUE; int sum=0 ; int i=0 ; for (int j=0 ;j<nums.length;j++) { sum+=nums[j]; while (sum>=target) { int slength = j-i+1 ; result = Math.min(result,slength); sum -= nums[i++]; } } return result==Integer.MAX_VALUE?0 :result; } }
暴力破解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int result=Integer.MAX_VALUE; int sum=0 ; for (int i=0 ;i<nums.length;i++){ sum = 0 ; for (int j=i;j<nums.length;j++){ sum+=nums[j]; if (sum>=target){ int slength = j-i+1 ; result = Math.min(result,slength); break ; } } } return result==Integer.MAX_VALUE?0 :result; }
59螺旋矩阵 而求解本题依然是要坚持循环不变量原则。
模拟顺时针画矩阵的过程:
填充上行从左到右
填充右列从上到下
填充下行从右到左
填充左列从下到上
由外向内一圈一圈这么画下去。
这里一圈下来,我们要画每四条边,这四条边怎么画,每画一条边都要坚持一致的左闭右开,或者左开右闭的原则,这样这一圈才能按照统一的规则画下来。
那么我按照左闭右开的原则,来画一圈,大家看一下:
这里每一种颜色,代表一条边,我们遍历的长度,可以看出每一个拐角处的处理规则,拐角处让给新的一条边来继续画。
这也是坚持了每条边左闭右开的原则。
一些同学做这道题目之所以一直写不好,代码越写越乱。
就是因为在画每一条边的时候,一会左开右闭,一会左闭右闭,一会又来左闭右开,岂能不乱。
代码里处理的原则也是统一的左闭右开。
需要循环几次,可以将行在中间分割两半,一半看能分成几层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution { public int [][] generateMatrix(int n) { int loop = 0 ; int [][] res = new int [n][n]; int start = 0 ; int count = 1 ; int i,j; while (loop++<n/2 ) { for (j=start;j<n-loop;j++) res[start][j] = count++; for (i=start;i<n-loop;i++) res[i][j] = count++; for (j=j;j>=loop;j--) res[i][j] = count++; for (i=i;i>=loop;i--) res[i][j] = count++; start++; } if (n%2 ==1 ) res[start][start] = count; return res; } }
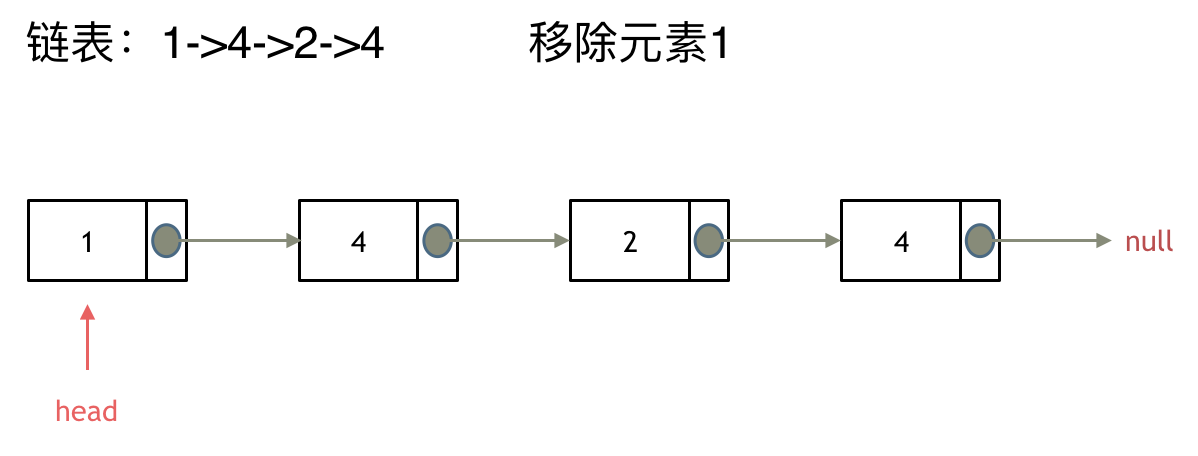
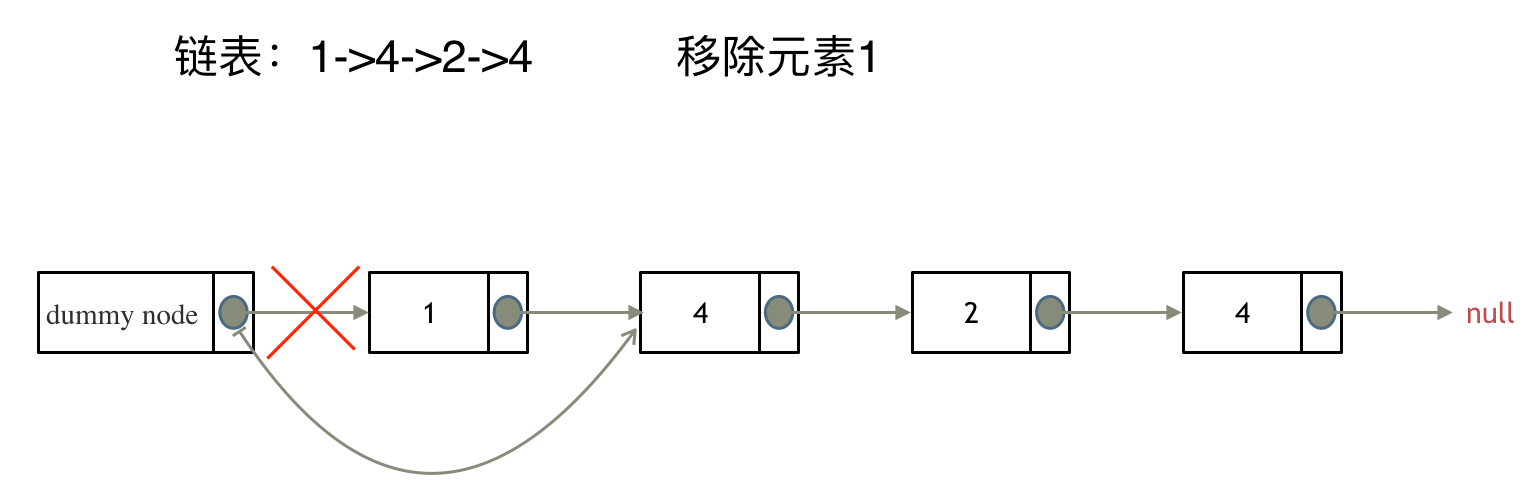
203.移除链表元素
直接使用原来的链表来进行删除操作。 设置一个虚拟头结点在进行删除操作。
来看第一种操作:直接使用原来的链表来进行移除。
移除头结点和移除其他节点的操作是不一样的,因为链表的其他节点都是通过前一个节点来移除当前节点,而头结点没有前一个节点。
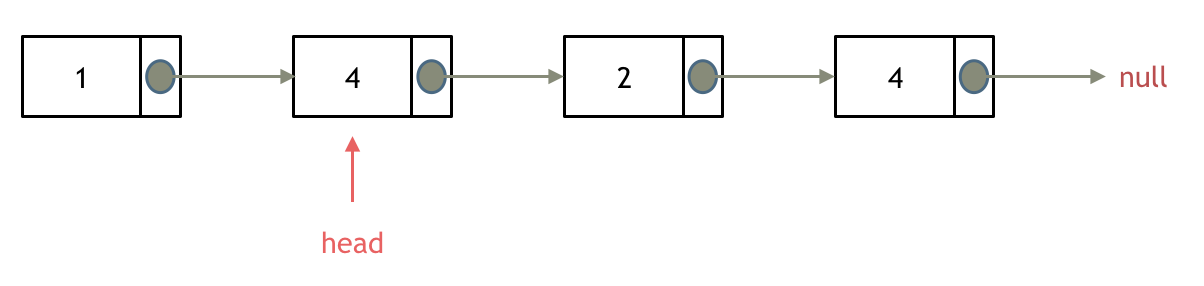
所以头结点如何移除呢,其实只要将头结点向后移动一位就可以,这样就从链表中移除了一个头结点。
依然别忘将原头结点从内存中删掉。
这样移除了一个头结点,是不是发现,在单链表中移除头结点 和 移除其他节点的操作方式是不一样,其实在写代码的时候也会发现,需要单独写一段逻辑来处理移除头结点的情况。
那么可不可以 以一种统一的逻辑来移除 链表的节点呢。
其实可以设置一个虚拟头结点 ,这样原链表的所有节点就都可以按照统一的方式进行移除了。
来看看如何设置一个虚拟头。依然还是在这个链表中,移除元素1。
这里来给链表添加一个虚拟头结点为新的头结点,此时要移除这个旧头结点元素1。
这样是不是就可以使用和移除链表其他节点的方式统一了呢?
来看一下,如何移除元素1 呢,还是熟悉的方式,然后从内存中删除元素1。
最后呢在题目中,return 头结点的时候,别忘了 return dummyNode->next;, 这才是新的头结点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public ListNode removeElements (ListNode head, int val) { while (head!=null &&head.val==val) { head = head.next; } ListNode cur = head; while (cur!=null ){ while (cur.next!=null &&cur.next.val==val) { cur.next = cur.next.next; } cur = cur.next; } return head; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution { public ListNode removeElements (ListNode head, int val) { if (head == null ) { return head; } ListNode pre = new ListNode (-1 ,head); ListNode cur = pre; while (cur.next!=null ){ if (cur.next.val==val) { cur.next = cur.next.next; } else { cur = cur.next; } } return pre.next; } }
思路:克隆树和原树数据一样,并且元素唯一,不会重复。原树和clone树同时遍历。原树节点等于target的话就返回clone对应节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public final TreeNode getTargetCopy (final TreeNode original, final TreeNode cloned, final TreeNode target) { if (original == null ) return null ; if (original == target) return cloned; TreeNode left = getTargetCopy(original.left,cloned.left, target); if (left != null ) return left; return getTargetCopy(original.right,cloned.right, target); } }
拆分中序,再拆分后续 左开右闭
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution { Map<Integer,Integer> map ; public TreeNode buildTree (int [] inorder, int [] postorder) { map = new HashMap <>(); for (int i=0 ;i<inorder.length;i++) { map.put(inorder[i],i); } return dfs(inorder,0 ,inorder.length,postorder,0 ,postorder.length); } TreeNode dfs (int [] inorder,int startIn,int endIn, int [] postorder,int startPost,int endPost) { if (startIn>=endIn||startPost>=endPost) { return null ; } int rootIndex = map.get(postorder[endPost-1 ]); TreeNode root = new TreeNode (inorder[rootIndex]); int leftLength = rootIndex-startIn; root.left = dfs(inorder,startIn,rootIndex,postorder,startPost,startPost+leftLength); root.right = dfs(inorder,rootIndex+1 ,endIn,postorder,startPost+leftLength,endPost-1 ); return root; } }
654.最大二叉树 首先确定参数和返回值 参数是操作的数组,起始值,终止值 返回值是root节点
确定终止的条件:终止值<起始值就数组为null,直接返回空节点
中间过程:首先找出最大值和最大值所在的位置 让最大值作为根节点 用位置确定划分左右子树
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Solution { public TreeNode constructMaximumBinaryTree (int [] nums) { return constructMaxTree(nums, 0 , nums.length); } TreeNode constructMaxTree (int [] nums, int begin, int end) { if (end - begin < 1 ) return null ; if (end - begin == 1 ) return new TreeNode (nums[begin]); int maxValue = nums[begin]; int maxIndex = begin; for (int i = begin + 1 ; i < end; i++) { if (nums[i] > maxValue) { maxValue = nums[i]; maxIndex = i; } } TreeNode node = new TreeNode (maxValue); node.left = constructMaxTree(nums, begin, maxIndex); node.right = constructMaxTree(nums, maxIndex + 1 , end); return node; } }
700.二叉搜索树中的搜索 给定二叉搜索树(BST)的根节点 root 和一个整数值 val。
你需要在 BST 中找到节点值等于 val 的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 null 。
思路:
dfs:递归搜索目标节点,遇到直接返回
迭代:因为是二叉搜索树,满足左小右大,小于根节点就向左,大于就向右寻找,找到就返回
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution { public TreeNode searchBST (TreeNode root, int val) { if (root == null || root.val == val) return root; TreeNode result = null ; if (root.val > val) { result = searchBST(root.left, val); } if (root.val < val) { result = searchBST(root.right, val); } return result; } } class Solution { public TreeNode searchBST (TreeNode root, int val) { while (root!=null ) { if (root.val>val) root= root.left ; else if (root.val<val) root = root.right; else return root; } return null ; } }
二叉搜索树的中序遍历是升序,我们将节点保存到数组中,然后判断一下数组是否是升序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 class Solution { List<Integer> list = new ArrayList <>(); public boolean isValidBST (TreeNode root) { if (root == null ) return true ; isValid(root, list); boolean flag = true ; for (int i = 1 ; i < list.size(); i++) { if (list.get(i - 1 ) >= list.get(i)) { flag = false ; break ; } } return flag; } void isValid (TreeNode root, List list) { if (root.left != null ) isValid(root.left, list); list.add(root.val); if (root.right != null ) isValid(root.right, list); } } class Solution { TreeNode preNode ; public boolean isValidBST (TreeNode root) { if (root == null ) return true ; boolean left = isValidBST(root.left); if (!left) return false ; if (preNode!=null && root.val<=preNode.val) return false ; preNode = root; return isValidBST(root.right); } }
双指针 双指针解法
因为数组是有序的,所以可以定义左右指针,相加大于target就right–,相反则left++,相等返回 O(n)
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public int [] twoSum(int [] numbers, int target) { int left = 0 , right = numbers.length - 1 ; while (left < right) { if (numbers[left] + numbers[right] == target) return new int [] { left+1 , right+1 }; else if (numbers[left] + numbers[right] > target) right--; else left++; } return new int [] { 0 }; } }
首先进行排序,然后判断首位是否大于0,对i去重,sum进行上面判断,需要对left和right去重
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution { public List<List<Integer>> threeSum (int [] nums) { List<List<Integer>> resList = new ArrayList <>(); Arrays.sort(nums); for (int i = 0 ; i < nums.length; i++) { if (nums[i] > 0 ) return resList; if (i > 0 && nums[i] == nums[i - 1 ]) continue ; int left = i + 1 ; int right = nums.length - 1 ; while (left < right) { int sum = nums[i] + nums[left] + nums[right]; if (sum > 0 ) right--; else if (sum < 0 ) left++; else { resList.add(Arrays.asList(nums[i], nums[left], nums[right])); while (right > left && nums[left] == nums[left + 1 ]) left++; while (right > left && nums[right] == nums[right - 1 ]) right--; left++; right--; } } } return resList; } }
思路双指针 找最大面积,初始化一个面积,左右指针,计算面积,更新最大面积,左边高度小就往左移,右边高度小就往右移动
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public int maxArea (int [] height) { int maxA = 0 ; int left = 0 ; int right = height.length - 1 ; while (left < right) { int area = Math.min(height[left], height[right]) * (right - left); maxA = Math.max(area, maxA); if (height[right] < height[left]) right--; else left++; } return maxA; } }
滑动窗口 双指针,计算sum的值是否大于target 大于的话则更新长度,将左指针的数剪掉判断是否还大于target,left需要++ 在返回时也需要判断返回的长度是不是比初始的长度小于或者等于,满足则可直接返回,不行则返回0
双指针在满足单调性的时候可以使用
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public int minSubArrayLen (int target, int [] nums) { int minSub = nums.length+1 ; int sum = 0 ; int left = 0 ; for (int right = 0 ;right<nums.length;right++) { sum += nums[right]; while (sum>=target) { minSub = Math.min(minSub,right-left+1 ); sum -= nums[left]; left++; } } return minSub <= nums.length ? minSub:0 ; } }
k<=1 子数组不存在,直接返回0
个数 是右指针减去左指针+1 都是从满足的左指针的下一位开始到右指针
满足* 然后去掉左边的数 判断是否满足,不满足就去算个数
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public int numSubarrayProductLessThanK (int [] nums, int k) { if (k<=1 ) return 0 ; int ans = 0 ; int cj = 1 ; int l = 0 ; for (int r = 0 ; r < nums.length; r++) { cj *= nums[r]; while (cj >= k) { cj /= nums[l]; l += 1 ; } ans += r-l+1 ; } return ans; } }
滑动窗口 利用hashSet来判断集合里面是否有元素,有元素的话最左侧集合元素右移 ,没元素的话将其加入 将字符串转为字符数组,用boolean数组来替换hashSet
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class Solution { public int lengthOfLongestSubstring (String S) { int max = 0 ; int left = 0 ; char [] s = S.toCharArray(); boolean [] has = new boolean [128 ]; for (int right = 0 ; right < s.length; right++) { char c = s[right]; while (has[c]) { has[s[left++]] = false ; } has[c] = true ; max = Math.max(max,right-left+1 ); } return max; } } class Solution { public int lengthOfLongestSubstring (String S) { int max = 0 ; int left = -1 ; char [] s = S.toCharArray(); Map<Character, Integer> has = new HashMap <>(); for (int right = 0 ; right < s.length; right++) { char c = s[right]; if (has.containsKey(c)){ left = Math.max(left,has.get(c)); } has.put(c,right); max = Math.max(max,right-left); } return max; } }
二分查找 解题思路:二分查找low_bound 【时间复杂度O(lgn),n是数组长度】
- 核心要素
- 有序数组中二分查找的四种类型(下面的转换仅适用于数组中都是整数)
1. 第一个大于等于x的下标: low_bound(x)
2. 第一个大于x的下标:可以转换为第一个大于等于 x+1 的下标 ,low_bound(x+1)
3. 最后一个一个小于x的下标:可以转换为第一个大于等于 x 的下标 的左边位置, low_bound(x) - 1;
4. 最后一个小于等于x的下标:可以转换为`第一个大于等于 x+1 的下标` 的 `左边位置`, low_bound(x+1) - 1;
//第一个出现的位置 就是>=target的位置
闭区间 mid + 1 mid -1
左闭右开 mid+1 mid
左开右闭 start=-1 mid mid+1
循环不变量 最后的时候
“红蓝染色法”关键:
right 左移使右侧变蓝 (判断条件为 true )
left 右移使左侧变红 (判断条件为 false )
故确定二分处 ( mid ) 的染色条件是关键 闭区间,和判断条件相同的话就是什么颜色
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution { public int [] searchRange(int [] nums, int target) { int start = midBound(nums,target); if (start==nums.length || nums[start]!=target) return new int []{-1 ,-1 }; int end = midBound(nums,target+1 )-1 ; return new int []{start,end}; } int midBound (int [] nums, int target) { int start = 0 ; int end = nums.length-1 ; while (start<=end) { int mid = start+(end-start)/2 ; if (nums[mid]<target) { start = mid+1 ; } else { end = mid-1 ; } } return start; } }
根据红黑染色法,蓝色代表峰顶及其峰顶右侧的值,数组中一定有封顶存在,所以最后一个肯定是蓝色,红色代表封顶左侧的值
比较 mid和mid+1的值
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public int findPeakElement (int [] nums) { int left = 0 ; int right = nums.length-2 ; while (left<=right) { int mid = left+(right-left) / 2 ; if (nums[mid]<nums[mid+1 ]) { left = mid +1 ; } else { right = mid -1 ; } } return left; } }
红蓝标记法,红色代表大于最小数,蓝色代表小于等于最小的数 拿中间值和最后一个数进行比较 小于最后值,right-1 大于最后的值 left+1
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public int findMin (int [] nums) { int left = 0 ; int right = nums.length - 2 ; while (left <= right) { int mid = left + (right - left) / 2 ; if (nums[mid] > nums[nums.length - 1 ]) { left = mid + 1 ; } else { right = mid - 1 ; } } return nums[left]; } }
堆 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 class Solution { public int [] topKFrequent(int [] nums, int k) { Map<Integer, Integer> map = new HashMap <>(); for (int num : nums) { map.put(num, map.getOrDefault(num,0 ) + 1 ); } PriorityQueue<int []> queue = new PriorityQueue <>((p1, p2) -> (p1[1 ] - p2[1 ])); for (Map.Entry<Integer, Integer> entry : map.entrySet()) { if (queue.size() < k) { queue.add(new int [] { entry.getKey(), entry.getValue() }); } else { if (entry.getValue() > queue.peek()[1 ]) { queue.poll(); queue.add(new int [] { entry.getKey(), entry.getValue() }); } } } int [] res = new int [k]; for (int i = k - 1 ; i >= 0 ; i--) { res[i] = queue.poll()[0 ]; } return res; } } class Solution { public int [] topKFrequent(int [] nums, int k) { Map<Integer, Integer> map = new HashMap <>(); for (int num : nums) { map.put(num, map.getOrDefault(num, 0 ) + 1 ); } PriorityQueue<int []> queue = new PriorityQueue <>((p1, p2) -> (p2[1 ] - p1[1 ])); for (Map.Entry<Integer, Integer> entry : map.entrySet()) { queue.add(new int [] { entry.getKey(), entry.getValue() }); } int [] res = new int [k]; for (int i = k - 1 ; i >= 0 ; i--) { res[i] = queue.poll()[0 ]; } return res; } }
反转链表 反转链表Ⅰ 先保存后一个节点(避免最后当前节点不能后移),然后指向前一个节点,前一个节点后移,当前节点也后移
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public ListNode reverseList (ListNode head) { if (head==null ) { return null ; } ListNode pre = null ; while (head!=null ) { ListNode lastNode = head.next; head.next = pre; pre = head; head = lastNode; } return pre; } }
首先申请一个节点dummy ,p0让其指向head 然后dummy到left的左一个节点,然后让其后一个节点(left)为cur,申请一个null节点做反转,可以从测试样例看出执行次数是right+left-1,反转和之前一样,先保存后一个节点,然后指向前一个节点,前一个节点后移,当前节点也后移 最后让p0.next.next=cur p0.next=pre
cur会指向最后一个节点,pre会指向后一个节点的前一个节点
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { public ListNode reverseBetween (ListNode head, int left, int right) { ListNode dummy = new ListNode (0 , head); ListNode p0 = dummy; for (int i = 0 ; i < left - 1 ; i++) p0 = p0.next; ListNode pre = null ; ListNode cur = p0.next; for (int i = 0 ; i < right - left +1 ; i++) { ListNode lastNode = cur.next; cur.next = pre; pre = cur; cur = lastNode; } p0.next.next = cur; p0.next = pre; return dummy.next; } }
快慢指针
快指针走两步,慢指针走一步
最后快指针在null或者在最后一个节点,慢指针在中间位置
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { public ListNode removeNthFromEnd (ListNode head, int n) { ListNode dummy = new ListNode (0 ,head); ListNode fast = head; while (n>0 ){ fast = fast.next; n--; } ListNode slow = dummy; while (fast!=null ) { fast = fast.next; slow = slow.next; } slow.next = slow.next.next; return dummy.next; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution { public ListNode middleNode (ListNode head) { ListNode fast = head; ListNode slow = head; while (fast!=null && fast.next!=null ) { fast = fast.next.next; slow = slow.next; } return slow; } }
环,快慢指针总会相遇,并且快指针追到慢指针,慢慢指针进入环后循环次数小于环的长度
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class Solution { public boolean hasCycle (ListNode head) { ListNode fast = head; ListNode slow = head; while (fast!=null && fast.next!=null ) { fast = fast.next.next; slow = slow.next; if (slow==fast) { return true ; } } return false ; } }
两个节点相遇后,让其中一个节点从head从新开始走,另一个节点继续一步一步走,两者会在入口相遇。
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class Solution { public ListNode detectCycle (ListNode head) { ListNode fast = head; ListNode slow = head; while (fast != null && fast.next != null ){ fast = fast.next.next; slow = slow.next; if (fast==slow) { ListNode index1 = head; ListNode index2 = fast; while (index1!=index2) { index1 = index1.next; index2 = index2.next; } return index1; } } return null ; } }
最终想得到的数据是 1->5->2->4->3 先走第一个然后倒数第一个 然后第二个倒数第二个
首先通过快慢指针找到中间节点,然后将其及其后面反转。 让最后一个节点为head2 保留head和head2的下一个节点,头结点指向head2。然后往后走,循环直到head2的next指向null
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 class Solution { ListNode midNode (ListNode head) { ListNode fast = head; ListNode slow = head; while (fast != null && fast.next != null ) { slow = slow.next; fast = fast.next.next; } return slow; } ListNode reverseNode (ListNode head) { ListNode temp = null ; while (head != null ) { ListNode lastNode = head.next; head.next = temp; temp = head; head = lastNode; } return temp; } public void reorderList (ListNode head) { ListNode mid = midNode(head); ListNode head2 = reverseNode(mid); while (head2.next != null ) { ListNode hNode1 = head.next; ListNode hNode2 = head2.next; head.next = head2; head2.next = hNode1; head = hNode1; head2 = hNode2; } } }
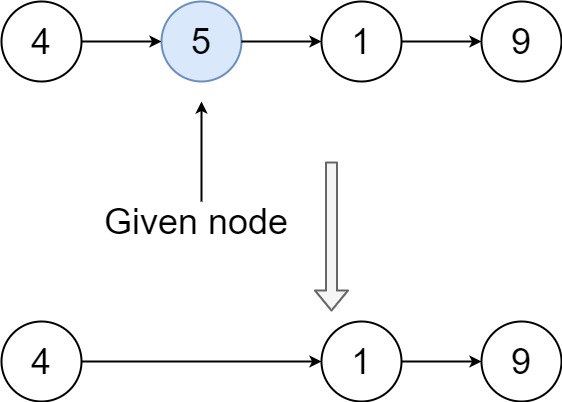
前后指针 单链表想要删除一个节点需要获取上一个节点,但是如果题目只给你要删除的节点,不知道上一个节点是什么,该怎么做? 见237
有一个单链表的 head,我们想删除它其中的一个节点 node。
给你一个需要删除的节点 node 。你将 无法访问 第一个节点 head。
链表的所有值都是 唯一的 ,并且保证给定的节点 node 不是链表中的最后一个节点。
删除给定的节点。注意,删除节点并不是指从内存中删除它。这里的意思是:
给定节点的值不应该存在于链表中。
链表中的节点数应该减少 1。
node 前面的所有值顺序相同。node 后面的所有值顺序相同。
自定义测试:
对于输入,你应该提供整个链表 head 和要给出的节点 node。node 不应该是链表的最后一个节点,而应该是链表中的一个实际节点。
我们将构建链表,并将节点传递给你的函数。
输出将是调用你函数后的整个链表。
示例 1:
1 2 3 输入:head = [4,5,1,9], node = 5 输出:[4,1,9] 解释:指定链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9
思路:将想要删除的节点的下一节点的值copy到要删除节点。然后将node.next指向node.next.next节点
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution { public void deleteNode (ListNode node) { node.val = node.next.val; node.next = node.next.next; } }
判断是不是需要申请前缀节点 :唯一就是head节点是否会被删除
本题:n可能等于链表长度 n就会等于头结点了 。所以需要申请前缀节点让其指向head
先让快指针向前走n步,然后让慢指针和快指针一块走。最后让慢指针的next指向next.next 返回前缀节点的next
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public ListNode removeNthFromEnd (ListNode head, int n) { ListNode dummy = new ListNode (0 ,head); ListNode fast = head; while ((n--)>0 ) { fast = fast.next; } ListNode slow = dummy; while (fast!=null ) { fast = fast.next; slow = slow.next; } slow.next = slow.next.next; return dummy.next; } }
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
cur = head 然后遍历,查看是否和后面节点相同,相同的话就指向next.next
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public ListNode deleteDuplicates (ListNode head) { if (head==null ) { return null ; } ListNode cur = head; while (cur.next!=null ) { if (cur.val==cur.next.val) { cur.next = cur.next.next; } else { cur = cur.next; } } return head; } }
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
可能head节点也为重复元素,需要删除 所以需要申请一个dummy节点
cur = dummy判断cur.next和cur.next.next节点是否相同,相同的话然后去循环删除这个重复的节点(判断是否下一节点和重复的值相同,相同就指向后一个节点),不相同的话,让cur节点指向下一个节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution { public ListNode deleteDuplicates (ListNode head) { ListNode dummy = new ListNode (-1 , head); ListNode cur = dummy; while (cur.next != null && cur.next.next != null ) { int val = cur.next.val; if (val == cur.next.next.val) { while (cur.next!=null && cur.next.val == val) { cur.next = cur.next.next; } } else { cur = cur.next; } } return dummy.next; } }
递归 获取左子树的深度和右子树的深度,判断哪个大,然后+1
非全局变量法
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Solution { public int maxDepth (TreeNode root) { if (root==null ) return 0 ; int llength = maxDepth(root.left); int rlength = maxDepth(root.right); return Math.max(llength,rlength) + 1 ; } } class Solution { private int ans; public int maxDepth (TreeNode root) { dfs(root,0 ); return ans; } public void dfs (TreeNode node,int cnt) { if (node==null ) return ; ++cnt; ans = Math.max(ans,cnt); dfs(node.left,deep); dfs(node.right,deep); } }
遍历p树和q树,让p的左树和q的左树相同,p的r和q的r相同就返回 true 结束条件是p或者q为null 两者都为null,返回true
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public boolean isSameTree (TreeNode p, TreeNode q) { if (p==null || q==null ) return p==q; return p.val == q.val && isSameTree(p.left,q.left) && isSameTree(p.right,q.right); } }
遍历树,树的左树和树的右树相同,左树的左节点和右树的右节点相同,左数的右节点和右树的左节点相同就为 true 结束条件是p或者q为null 两者都为null,返回true
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public boolean isSymmetric (TreeNode root) { return isSameTree(root.left,root.right); } boolean isSameTree (TreeNode p , TreeNode q) { if (p==null || q==null ) return p==q; return p.val == q.val && isSameTree(p.left,q.right) && isSameTree(p.right,q.left); } }
左右高度的绝对值为1就是平衡二叉树。可以设置为-1为不平衡,在归的过程中,如果出现等于-1的话,直接返回-1 不是-1就返回它的高度 最后判断是不是等于-1,
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution { public boolean isBalanced (TreeNode root) { return getHeight(root)==-1 ?false :true ; } int getHeight (TreeNode root) { if (root==null ) return 0 ; int llength = getHeight(root.left); if (llength==-1 ) { return -1 ; } int rlength = getHeight(root.right); if (rlength==-1 ) { return -1 ; } if (Math.abs(llength-rlength) > 1 ) { return -1 ; } return Math.max(llength,rlength)+1 ; } }
dfs:可以用高度和集合大小,来找右视图。必须先递归右子树,然后递归左子树 判断高度是不是等于集合长度,等于就把val加入集合,
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { List<Integer> resList = new ArrayList <>(); public List<Integer> rightSideView (TreeNode root) { dfs(root, 0 ); return resList; } void dfs (TreeNode root, int ans) { if (root==null ) return ; if (ans == resList.size()) resList.add(root.val); ans++; dfs(root.right,ans); dfs(root.left,ans); } }
bfs:队列解题,可以通过队列来判断,for循环 i是队列的长度的时候就记录下来
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution { List<Integer> resList = new ArrayList <>(); public List<Integer> rightSideView (TreeNode root) { if (root==null ) return resList; Deque<TreeNode> que = new LinkedList (); que.offerLast(root); while (!que.isEmpty()){ int len = que.size(); for (int i=0 ;i<len;i++) { TreeNode node = que.poll(); if (i==len-1 ) resList.add(node.val); if (node.left!=null ) que.addLast(node.left); if (node.right!=null ) que.addLast(node.right); } } return resList; } }
验证二叉搜索树 前序遍历:
初始化根节点的范围为 负无穷到正无穷 判断节点是否在这个区间内,向左子树遍历,让其右范围更新为上一节点的值,让其在负无穷到上一节点值之间 向右子树遍历,让其左范围更新为上一节点的值,让其在上一节点值到正无穷之间
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution { public boolean isValidBST (TreeNode root) { return isValidBST(root,Long.MIN_VALUE,Long.MAX_VALUE); } boolean isValidBST (TreeNode root,long left,long right) { if (root==null ) { return true ; } int x = root.val; return left<x && x<right && isValidBST(root.left,left,x) && isValidBST(root.right,x,right); } }
中序遍历
是一个升序,让其判断当前节点和上一节点的大小,先走到最左侧节点,然后往上遍历,如果不满足,直接向上返回false 当前节点大于上一节点就是升序,否则不是 更新前缀的节点为当前节点继续遍历 初始化根节点的上一节点为null
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { TreeNode pre; public boolean isValidBST (TreeNode root) { if (root == null ) return true ; boolean left = isValidBST(root.left); if (!left) return false ; int x = root.val; if (pre!=null && x <= pre.val) { return false ; } pre = root; return isValidBST(root.right); } }
后序遍历 :
如果是null,然后返回最小值和最大值分别为正无穷和负无穷,然后遍历左子树拿去最小值和最大值。遍历右子树拿去最小值和最大值,获取当前节点的值,去比较 是不是大于左子树的最大值,和小于右子树的最小值。不满足的话返回最小值为负无穷 最大值为正无穷 返回当前节点值和左侧最小值,当前节点值和右侧最大值(因为会有无穷)
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public boolean isValidBST (TreeNode root) { return dfs(root)[1 ] != Long.MAX_VALUE; } private long [] dfs(TreeNode node) { if (node == null ) { return new long [] { Long.MAX_VALUE, Long.MIN_VALUE }; } long [] left = dfs(node.left); long [] right = dfs(node.right); int x = node.val; if (x <= left[1 ] || x >= right[0 ]) { return new long [] { Long.MIN_VALUE, Long.MAX_VALUE }; } return new long [] { Math.min(x, left[0 ]), Math.max(x, right[1 ]) }; } }
排序算法 冒泡排序: 升序 , 当前值大于后一个值,发生交换,交换次数是j-i-1 因为每一轮执行完之后都会有已经排好序的
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public int [] sortArray(int [] nums) { for (int i = 0 ;i<nums.length-1 ;i++) { for (int j = 0 ; j<nums.length-1 -i ; j++) { if (nums[j]>nums[j+1 ]) { int temp = nums[j]; nums[j] = nums[j+1 ]; nums[j+1 ] = temp; } } } return nums; }
优化冒泡排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public int [] sortArray(int [] nums) { for (int i = 0 ;i<nums.length-1 ;i++) { boolean flag = true ; for (int j = 0 ; j<nums.length-1 -i ; j++) { if (nums[j]>nums[j+1 ]) { int temp = nums[j]; nums[j] = nums[j+1 ]; nums[j+1 ] = temp; flag = false ; } } if (flag) { break ; } } return nums; }
选择排序: 每一轮寻找最小的数和最前面进行交换,直到最后有序
每轮找到最小的值,结束后把它和头部进行交换
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public int [] sortArray(int [] nums) { for (int i = 0 ; i < nums.length; i++) { int minIndex = i; for (int j = i + 1 ; j < nums.length; j++) { if (nums[j] < nums[minIndex]) { minIndex = j; } } int temp = nums[i]; nums[i] = nums[minIndex]; nums[minIndex] = temp; } return nums; }
插入排序: 时间复杂度是 O(n^2) 适合数组短的排序 因为「短数组」的特点是:每个元素离它最终排定的位置都不会太远 并且在数组「几乎有序」 的前提下,「插入排序」的时间复杂度可以达到 O(N)
思路:将一个数字插入到有序的数组里,成为一个更长的有序数组,一段时间后数组有序
从第二个数开始,和前面的数做比较,如果小于前面的数就交换,依次进行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public int [] sortArray(int [] nums) { int len = nums.length; for (int i=1 ;i<len;i++) { for (int j = i ; j>0 && nums[j]<nums[j-1 ];j--) { if (nums[j]<nums[j-1 ]) { swap(nums,j,j-1 ); } } } return nums; } static void swap (int [] nums,int a,int b) { int temp = nums[a]; nums[a] = nums[b]; nums[b] = temp; } }
**优化 ** 不使用swap方法,使用临时变量来存储当前值,然后让前面的数后移,将这个临时变量在放到前面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public int [] sortArray(int [] nums) { int len = nums.length; for (int i = 1 ; i < len; i++) { int temp = nums[i]; int j = i; while (j > 0 && temp < nums[j - 1 ]) { nums[j] = nums[j - 1 ]; j--; } nums[j] = temp; } return nums; } }
最近的公共祖先 递归 如果节点为null或者为p或者为q 就返回当前节点
然后遍历左子树 和右子树 得到返回结果,判断 如果左右子树都找到就返回当前节点,只在左树找到返回递归左子树的结果,只在右树找到返回递归右子树的结果,如果都没找到返回null
遇到pq就返回,不需继续遍历,因为他已经是一个节点,无论q还是p在后面都是要返回这个节点
pq在左右两侧返回当前节点,在右侧返回右侧 在左侧返回左侧
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public TreeNode lowestCommonAncestor (TreeNode root, TreeNode p, TreeNode q) { if (root == null || root == q || root == p) { return root; } TreeNode left = lowestCommonAncestor(root.left, p, q); TreeNode right = lowestCommonAncestor(root.right, p, q); if (left != null && right != null ) { return root; } if (left != null ) { return left; } return right; } }
二叉搜索树 满足左小右大,可以先判断pq分别属于哪部分,然后去递归子树。
pq都小于根节点,就去遍历左子树,然后返回 ;大于就去找右子树
如果qp在左右子树中,返回root, p或q是当前节点时也返回当前节点
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public TreeNode lowestCommonAncestor (TreeNode root, TreeNode p, TreeNode q) { if (root!=null && p.val<root.val && q.val<root.val) { return lowestCommonAncestor(root.left,p,q); } if (root!=null &&p.val>root.val && q.val>root.val) { return lowestCommonAncestor(root.right,p,q); } return root; } }
BFS 队列来完成,计算队列的大小,然后循环加入左右子树
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution { List<List<Integer>> res = new ArrayList <List<Integer>>(); public List<List<Integer>> levelOrder (TreeNode root) { if (root == null ) return res; Deque<TreeNode> queue = new LinkedList (); queue.offerLast(root); while (!queue.isEmpty()) { int len = queue.size(); List<Integer> list = new ArrayList <>(); while (len>0 ) { TreeNode node = queue.poll(); list.add(node.val); if (node.left!=null ) queue.addLast(node.left); if (node.right!=null ) queue.addLast(node.right); len--; } res.add(list); } return res; } }
奇数数组不变,偶数数组逆序
可以定义一个flag 第一层时奇数 flag=false 第二层是偶数 flag=true,在完成遍历后取反对flag,然后添加到列表中前判断是不是偶数还是奇数,偶数反转
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 class Solution { public List<List<Integer>> zigzagLevelOrder (TreeNode root) { List<List<Integer>> res = new ArrayList <List<Integer>>(); if (root == null ) return res; Deque<TreeNode> queue = new LinkedList (); queue.offerLast(root); boolean flag = false ; while (!queue.isEmpty()) { int len = queue.size(); List<Integer> list = new ArrayList <>(); while (len > 0 ) { TreeNode node = queue.poll(); list.add(node.val); if (node.left != null ) queue.addLast(node.left); if (node.right != null ) queue.addLast(node.right); len--; } if (flag) { Collections.reverse(list); res.add(list); } else { res.add(list); } flag = !flag; } return res; } }
两种方法:
第一种 :层序遍历,找到最后第一层,然后取第一个节点 可以定义一个cnt,然后每层第一个数都赋值,最后一个值就是最后一层的第一个值
第二种 :层序遍历,从右往左遍历,最后一个出队的节点的值就是答案 不需要去双重循环,然后直接拿出节点值就OK 每一个出队列都为node赋值,最后一个出的就是最底层最左侧的那个值
第一种代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution { public int findBottomLeftValue (TreeNode root) { Deque<TreeNode> queue = new LinkedList (); if (root == null ) return 0 ; queue.offerLast(root); TreeNode node = null ; int res = 0 ; while (!queue.isEmpty()) { int len = queue.size(); for (int i = 0 ; i < len; i++) { node = queue.pollFirst(); if (i == 0 ) res = node.val; if (node.left != null ) queue.addLast(node.left); if (node.right != null ) queue.addLast(node.right); } } return res; } }
第二种代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { public int findBottomLeftValue (TreeNode root) { Deque<TreeNode> queue = new LinkedList (); if (root==null ) return 0 ; queue.offerLast(root); TreeNode node = null ; while (!queue.isEmpty()) { node = queue.pollFirst(); if (node.right!=null ) queue.addLast(node.right); if (node.left!=null ) queue.addLast(node.left); } return node.val; } }
回溯 组合问题 向右 for循环遍历
向下 递归
回溯三部曲:
判断是否能够重复获取前面的元素
不能就有startIndex
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
1 2 3 4 5 6 7 8 9 10 输入:n = 4, k = 2 输出: [ [2,4], [3,4], [2,3], [1,2], [1,3], [1,4], ]
n代表可以取的值,k代表终止条件
定义一个path保存每个符合的结果,result集合保存最后的返回结果,startindex代表从哪个数开始进行遍历
终止:path.size大小==k
单层递归:从startIndex遍历,加入到path集合,然后递归从startIndex+1取值,然后回溯
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 class Solution { List<List<Integer>> resList = new ArrayList <>(); List<Integer> path = new ArrayList <>(); public List<List<Integer>> combine (int n, int k) { backstracking(n,k,1 ); return resList; } void backstracking (int n,int k,int startIndex) { if (path.size() == k) { resList.add(new ArrayList <>(path)); return ; } for (int i=startIndex;i<=n;i++) { path.add(i); backstracking(n,k,i+1 ); path.removeLast(); } } } class Solution { List<List<Integer>> resList = new ArrayList <>(); List<Integer> path = new ArrayList <>(); public List<List<Integer>> combine (int n, int k) { backstracking(n,k,1 ); return resList; } void backstracking (int n,int k,int startIndex) { if (path.size() == k) { resList.add(new ArrayList <>(path)); return ; } for (int i=startIndex;i<=n-(k-path.size())+1 ;i++) { path.add(i); backstracking(n,k,i+1 ); path.removeLast(); } } }
找出所有相加之和为 n 的 k 个数的组合,且满足下列条件:
返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。
示例 1:
1 2 3 4 5 输入: k = 3, n = 7 输出: [[1,2,4]] 解释: 1 + 2 + 4 = 7 没有其他符合的组合了。
剪枝操作:
sum大于n的话就无需再进行递归
至多到9-(k-midList.size())+1 ,才能满足mid集合里有k个元素 比如 k=2 至多到8 ,到9的话mid集合里面只能有1个元素,直接会不满足
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution { List<List<Integer>> resList = new ArrayList <>(); List<Integer> midList = new ArrayList <>(); public List<List<Integer>> combinationSum3 (int k, int n) { backtracing(0 , k, n, 1 ); return resList; } void backtracing (int targetSum, int k, int n, int startIndex) { if (midList.size() == k) { if (targetSum == n) { resList.add(new ArrayList <>(midList)); return ; } } for (int i = startIndex; i <= 9 - (k - midList.size()) + 1 ; i++) { if (targetSum > n) { return ; } targetSum = targetSum + i; midList.add(i); backtracing(targetSum, k, n, i + 1 ); targetSum = targetSum - i; midList.removeLast(); } } }
解题思路:
首先将对应关系保存到String集合里
定义全局遍历 s 和集合 reslist
参数:字符串 和 index代表是第几个数字
停止递归的条件是:当index和字符串的长度相同时,就将s放入reslist return
单层递归的逻辑:
首先获取数字对应的字符串
for循环,从0开始然后到字符串结束。 为什么不是startIndex 因为这是两个字母集合,然后不需要去判断是不是重复
然后将每个字符拼接到s中,然后递归,index+1
然后把放进去的字符拿出来
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { StringBuilder temp = new StringBuilder (); List<String> resList = new ArrayList <>(); public List<String> letterCombinations (String digits) { if (digits==null || digits.length()==0 ) { return resList; } String[] sarr = {"" ,"" ,"abc" ,"def" ,"ghi" ,"jkl" ,"mno" ,"pqrs" ,"tuv" ,"wxyz" }; trackbacking(digits,sarr,0 ); return resList; } void trackbacking (String digits,String[] sarr,int index) { if (index == digits.length()) { resList.add(temp.toString()); return ; } String ss = sarr[digits.charAt(index)-'0' ]; for (int i=0 ;i<ss.length();i++) { temp.append(ss.charAt(i)); trackbacking(digits,sarr,index+1 ); temp.deleteCharAt(temp.length()-1 ); } } }
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
示例 1:
1 2 3 4 5 6 输入:candidates = [2,3,6,7], target = 7 输出:[[2,2,3],[7]] 解释: 2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。 7 也是一个候选, 7 = 7 。 仅有这两种组合。
示例 2:
1 2 输入: candidates = [2,3,5], target = 8 输出: [[2,2,2,2],[2,3,3],[3,5]]
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution { public List<List<Integer>> combinationSum (int [] candidates, int target) { List<List<Integer>> res = new ArrayList <>(); Arrays.sort(candidates); backTracking(res, new ArrayList <>(), candidates, target, 0 , 0 ); return res; } void backTracking (List<List<Integer>> res, List<Integer> mid, int [] candidates, int target, int startIndex, int sum) { if (sum > target) { return ; } if (sum == target) { res.add(new ArrayList <>(mid)); return ; } for (int i = startIndex; i < candidates.length; i++) { if (sum + candidates[i] > target) break ; mid.add(candidates[i]); backTracking(res, mid, candidates, target, i, sum + candidates[i]); mid.remove(mid.size() - 1 ); } } }
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { List<List<Integer>> res = new ArrayList <>(); List<Integer> mid = new ArrayList <>(); public List<List<Integer>> combinationSum2 (int [] candidates, int target) { Arrays.sort(candidates); backTracking(candidates,target,0 ,0 ); return res; } void backTracking (int [] candidates, int target,int sum,int startIndex) { if (sum == target) { res.add(new ArrayList <>(mid)); return ; } for (int i=startIndex;i<candidates.length && sum + candidates[i] <= target;i++) { if (i>startIndex && candidates[i-1 ] == candidates[i]) { continue ; } sum+=candidates[i]; mid.add(candidates[i]); backTracking(candidates,target,sum,i+1 ); sum-=candidates[i]; mid.removeLast(); } } }
切割问题 如何分割,无重复的、判断回文字符串
递归终止条件:起始位置大于等于字符串的长度
单层递归:判断是否是回文字符串,是的话获取这个字段加入到集合中,不是的话直接跳过进行下一次循环。进行递归需要起始位置+1
回溯:mid集合最后一个位置删除
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Solution { List<List<String>> res = new ArrayList <>(); public List<List<String>> partition (String s) { backTracking(new ArrayList <>(), s, 0 ); return res; } void backTracking (List<String> mid, String s, int startIndex) { if (startIndex >= s.length()) { res.add(new ArrayList <>(mid)); } for (int i = startIndex; i < s.length(); i++) { if (isPalindrome(s, startIndex, i)) { String str = s.substring(startIndex, i+1 ); mid.add(str); } else { continue ; } backTracking(mid, s, i + 1 ); mid.remove(mid.size() - 1 ); } } boolean isPalindrome (String s, int start, int end) { for (int i = start, j = end; i < j; i++, j--) { if (s.charAt(i) != s.charAt(j)) { return false ; } } return true ; } }
找准怎么切割,是否需要起始点(不可重复),终止条件,单层递归
s转换为StringBuilder,效率更快 一次递归终止条件是 .的个数是3 并且第四个字段满足0-255 然后可以加入集合 并结束
单层递归, 判断是否符合0-255 符合在后面加入. 然后递归i+2(因为有个.).的个数也需要+1,然后回溯,将.删除就是i+1 不满足的话直接结束这次递归
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 class Solution { List<String> res = new ArrayList <>(); public List<String> restoreIpAddresses (String s) { StringBuilder sb = new StringBuilder (s); backTracking(sb, 0 , 0 ); return res; } void backTracking (StringBuilder sb, int startnum, int numSize) { if (numSize == 3 ) { if (valid(sb, startnum, sb.length() - 1 )) { res.add(sb.toString()); } return ; } for (int i = startnum; i < sb.length(); i++) { if (valid(sb, startnum, i)) { sb.insert(i + 1 , "." ); backTracking(sb, i + 2 , numSize + 1 ); sb.deleteCharAt(i + 1 ); } else { break ; } } } public boolean valid (StringBuilder s, int start, int end) { if (start > end) { return false ; } if (s.charAt(start) == '0' && start != end) { return false ; } int num = 0 ; for (int i = start; i <= end; i++) { if (s.charAt(i) > '9' || s.charAt(i) < '0' ) { return false ; } int size = s.charAt(i) - '0' ; num = num * 10 + size; if (num > 255 ) { return false ; } } return true ; } }
子集问题 需要保留每个树节点的子集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { List<List<Integer>> res = new ArrayList <>(); List<Integer> mid = new ArrayList <>(); public List<List<Integer>> subsets (int [] nums) { backtracking(nums, 0 ); return res; } void backtracking (int [] nums, int startIndex) { res.add(new ArrayList <>(mid)); if (startIndex >= nums.length) { return ; } for (int i = startIndex; i < nums.length; i++) { mid.add(nums[i]); backtracking(nums, i + 1 ); mid.removeLast(); } } }
树节点不能重复取相同的数。同树层不能有重复的元素
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution { List<List<Integer>> res = new ArrayList <>(); List<Integer> mid = new ArrayList <>(); public List<List<Integer>> subsetsWithDup (int [] nums) { Arrays.sort(nums); backtracking(nums, 0 ); return res; } void backtracking (int [] nums, int startIndex) { res.add(new ArrayList <>(mid)); if (startIndex >= nums.length) { return ; } for (int i = startIndex; i < nums.length; i++) { if (i > startIndex && nums[i] == nums[i - 1 ]) { continue ; } mid.add(nums[i]); backtracking(nums, i + 1 ); mid.removeLast(); } } }
子序列需要递增,需要去重(但是因为重复的不挨着不能用之前的来去重,需要用set集合来去重) set集合因为在一次循环里是相同的,同层就可以判断是不是取过值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { List<List<Integer>> result = new ArrayList <>(); List<Integer> path = new ArrayList <>(); public List<List<Integer>> findSubsequences (int [] nums) { backTracking(nums, 0 ); return result; } void backTracking (int [] nums, int startIndex) { if (path.size() > 1 ) { result.add(new ArrayList <>(path)); } Set<Integer> set = new HashSet <>(); for (int i = startIndex; i < nums.length; i++) { if (!path.isEmpty() && path.get(path.size() - 1 ) > nums[i] || set.contains(nums[i])) { continue ; } path.add(nums[i]); set.add(nums[i]); backTracking(nums, i + 1 ); path.removeLast(); } } }
排列问题 排列从0开始,不需要startIndex来标注是否使用过。用used布尔数组,使用过将对应位置设为true,来判断是否需要再一次记录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { List<List<Integer>> res = new ArrayList <>(); List<Integer> path = new LinkedList <>(); boolean [] used; public List<List<Integer>> permute (int [] nums) { used = new boolean [nums.length]; backTracking(nums); return res; } void backTracking (int [] nums) { if (nums.length == path.size()) { res.add(new LinkedList <>(path)); return ; } for (int i = 0 ; i < nums.length; i++) { if (used[i] == true ) continue ; used[i] = true ; path.add(nums[i]); backTracking(nums); path.removeLast(); used[i] = false ; } } }
47.全排列Ⅱ 给定一个可包含重复数字的序列 nums ,按任意顺序
示例 1:
1 2 3 4 5 输入:nums = [1,1,2] 输出: [[1,1,2], [1,2,1], [2,1,1]]
示例 2:
1 2 输入:nums = [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
提示:
1 <= nums.length <= 8-10 <= nums[i] <= 10
思路:同树层不可以使用之前使用过的数,使用set集合来查看是否用过同树层,利用used布尔数组来做排列
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { List<List<Integer>> res = new ArrayList <>(); List<Integer> path = new LinkedList <>(); boolean [] used; public List<List<Integer>> permuteUnique (int [] nums) { used = new boolean [nums.length]; backTracking(nums); return res; } void backTracking (int [] nums) { if (nums.length == path.size()) { res.add(new ArrayList <>(path)); return ; } Set set = new HashSet (); for (int i = 0 ; i < nums.length; i++) { if (!set.isEmpty() && set.contains(nums[i]) || used[i] == true ) { continue ; } set.add(nums[i]); path.add(nums[i]); used[i] = true ; backTracking(nums); path.removeLast(); used[i] = false ; } } }
第二种,不使用set集合。查看前后两个数是否相同,并且前面的数是否使用过
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { List<List<Integer>> res = new ArrayList <>(); List<Integer> path = new LinkedList <>(); boolean [] used; public List<List<Integer>> permuteUnique (int [] nums) { used = new boolean [nums.length]; Arrays.sort(nums); backTracking(nums); return res; } void backTracking (int [] nums) { if (nums.length == path.size()) { res.add(new ArrayList <>(path)); return ; } for (int i = 0 ; i < nums.length; i++) { if (i>0 && nums[i] == nums[i-1 ] && used[i-1 ] == true ) { continue ; } if (used[i] == false ) { path.add(nums[i]); used[i] = true ; backTracking(nums); path.removeLast(); used[i] = false ; } } } }
贪心问题 考虑局部最优,最终实现全局最优
先排序
可以考虑大的饼干去喂大的胃口,最终能实现最多。或者最小的胃口去选取最小的饼干。用第一种
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public int findContentChildren (int [] g, int [] s) { Arrays.sort(g); Arrays.sort(s); int index = s.length - 1 ; int res = 0 ; for (int i = g.length - 1 ; i >= 0 ; i--) { if (index >= 0 && s[index] >= g[i]) { index--; res++; } } return res; } }
如果只有一个数就直接返回nums[0],设为max为Integer最小值,因为可能出现都为-1的情况。count设置为0代表每个子数组的和从0开始。如果count+nums[i]小于0,就从nums[i+1]开始从count从新加
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public int maxSubArray (int [] nums) { if (nums.length == 1 ) { return nums[0 ]; } int sum = Integer.MIN_VALUE; int count = 0 ; for (int i = 0 ; i < nums.length; i++) { count += nums[i]; sum = Math.max(sum, count); if (count <= 0 ) { count = 0 ; } } return sum; } }
求上下摆动的次数。前后的差是正负数,就++
前后两个数相同就继续下一个循环
代码 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public int wiggleMaxLength (int [] nums) { if (nums == null ) { return 0 ; } if (nums.length < 2 ) return nums.length; int sum = 1 ; Boolean flag = null ; for (int i = 1 ; i < nums.length; i++) { if (nums[i] == nums[i - 1 ]) continue ; if (nums[i] - nums[i - 1 ] > 0 ) { if (flag != null && flag == true ) continue ; flag = true ; } else { if (flag != null && flag == false ) continue ; flag = false ; } sum++; } return sum; } }
首先可能会想到,找最小的价去买,找最高的价去卖,然后循环可以得到最大利润
也可以进行利润的拆分 找出每两天的利润差值,差值为正数就是获利,所有正值相加就是最大利润
第一天肯定没有利润,肯定第二天才会有利润
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution { public int maxProfit (int [] prices) { if (prices.length < 1 ) return 0 ; int sum = 0 ; for (int i = 1 ; i < prices.length; i++) { int c = prices[i] - prices[i - 1 ]; if (c > 0 ) { sum += c; } System.out.println(c); } return sum; } }
从前往后: 可以设一个cover代表从这个数开始能覆盖多长, 覆盖的长度如果超过了数组的长度,那么返回true
从前往后:可以设一个目标值(最后一个数),从倒数第二个开始,如果i加上这个数的位置超过目标值,就可以,将目标值赋值给i
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public boolean canJump (int [] nums) { if (nums.length<1 ) return true ; int cover = 0 ; for (int i = 0 ;i<=cover ; i++) { cover = Math.max(cover,i+nums[i]); if (cover>=nums.length-1 ) { return true ; } } return false ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public boolean canJump (int [] nums) { if (nums.length < 1 ) return true ; int tar = nums.length - 1 ; for (int i = nums.length - 2 ; i >= 0 ; i--) { if (i + nums[i] >= tar) tar = i; } return tar == 0 ; } }
可以有三个变量,一个是当前值覆盖的最远下标,第二个是下一个值覆盖的最远下标 第三个是步数
更新下一个值的最远下标 。如果下一个值的最远下标可以覆盖nums的长度,加一步就可以结束 。如果i到达当前值覆盖的最远下标,还没到达最后,需要向前走一步,将当前值更新为下一个值的最远下标
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public int jump (int [] nums) { if (nums == null || nums.length == 0 || nums.length == 1 ) { return 0 ; } int step = 0 ; int curcover = 0 ; int nextcover = 0 ; for (int i = 0 ; i < nums.length; i++) { nextcover = Math.max(nextcover, i + nums[i]); if (nextcover >= nums.length - 1 ) { step++; break ; } if (i == curcover) { curcover = nextcover; step++; } } return step; } }
正负转变k次,求数组和最大
按绝对值从大到小进行排序
将最大的绝对值尽可能放在前面,如果是负数就将其变为正数,k–
最后如果k还大于0,就将nums的最后一个值反复变号
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public int largestSumAfterKNegations (int [] nums, int k) { nums = IntStream.of(nums) .boxed() .sorted(((o1, o2) -> Math.abs(o2)-Math.abs(o1))) .mapToInt(Integer::intValue) .toArray(); for (int i = 0 ; i < nums.length; i++) { if (nums[i]<0 && k>0 ) { nums[i] = -nums[i]; k--; } } if (k%2 == 1 ) { nums[nums.length-1 ] = -nums[nums.length-1 ]; } return Arrays.stream(nums).sum(); } }
// 不要直接两边兼顾,先兼顾一边,右边的大于左边的 从头开始遍历
// 从后开始遍历,左边大于右边的 左边等于右边+1或者左边的大数不动
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public int candy (int [] ratings) { int len = ratings.length - 1 ; int [] candyVec = new int [ratings.length]; candyVec[0 ] = 1 ; for (int i = 1 ; i <= len; i++) { if (ratings[i] > ratings[i - 1 ]) { candyVec[i] = candyVec[i - 1 ] + 1 ; } else { candyVec[i] = 1 ; } } for (int i=len-1 ;i>=0 ;i--) { if (ratings[i] > ratings[i+1 ]) { candyVec[i] = Math.max(candyVec[i+1 ]+1 ,candyVec[i]); } } int n = 0 ; for (int i : candyVec) { n += i; } return n; } }

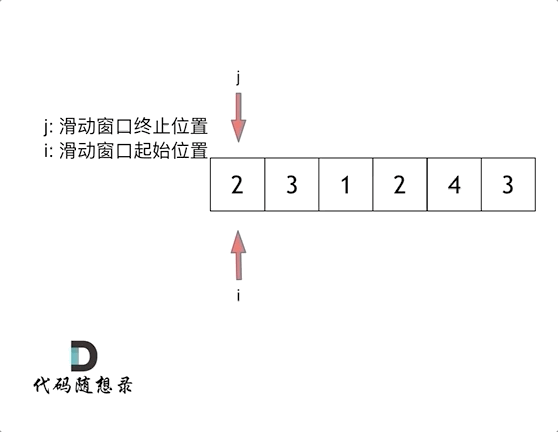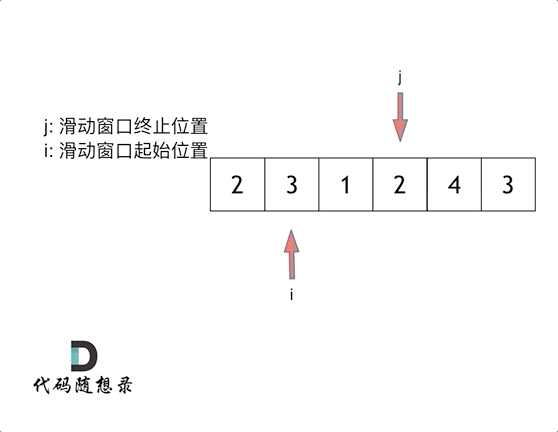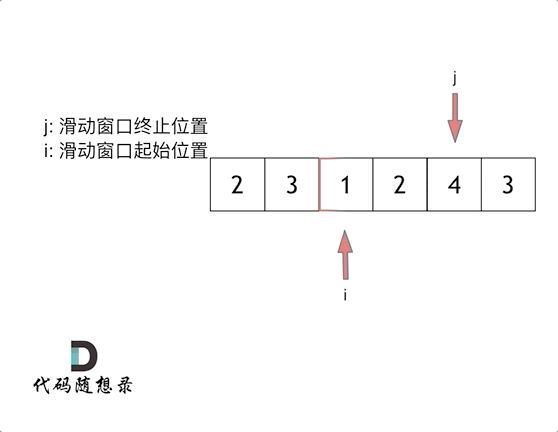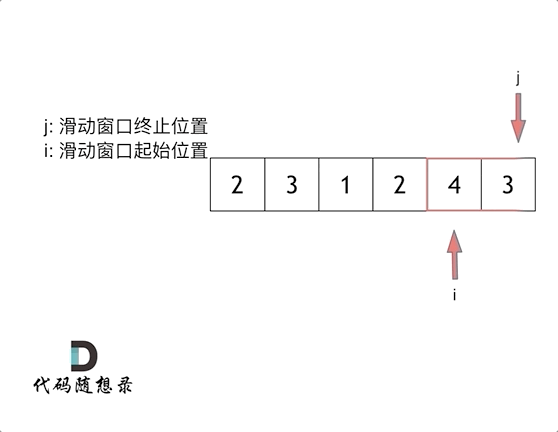

 这个图,递归左子树,高度又变为1和2 但是集合长度为3 不会加入,但是6的话和长度相同
这个图,递归左子树,高度又变为1和2 但是集合长度为3 不会加入,但是6的话和长度相同





